Lambert here: Holy moly. I guess that’s why the big push into AI, then: Regulatory arbitrage, Silicon Valley’s go-to play, in this case automatic and undetectable price-fixing. Cool.
By Emilio Calvano, Assistant Professor of Economics, University of Bologna, Giacomo Calzolari, Professor of Economics, EUI Florence, Bologna University ; Research Fellow CEPR, Vincenzo Denicolò, Professor of Economics, University of Bologna and University of Leicester (currently on leave); Research Fellow, CEPR, Sergio Pastorello, Professor of Econometrics, University of Bologna. Originally published at VoxEU.
Remember your last online purchase? Chances are, the price you paid was not set by humans but rather by a software algorithm. Already in 2015, more than a third of the vendors on Amazon.com had automated pricing (Chen et al. 2016), and the share has certainly risen since then – with the growth of a repricing software industry that supplies turnkey pricing systems, even the smallest vendors can now afford algorithmic pricing.
Unlike the traditional revenue management systems long in use by such businesses as airlines and hotels, in which the programmer remains effectively in charge of the strategic choices, the pricing programs that are now emerging are much more ‘autonomous’. These new algorithms adopt the same logic as the artificial intelligence (AI) programs that have recently attained superhuman performances in complex strategic environments such as the game of Go or chess. That is, the algorithm is instructed by the programmer only about the aim of the exercise – winning the game, say, or generating the highest possible profit. It is not told specifically how to play the game but instead learns from experience. In a training phase, the algorithm actively experiments with the alternative strategies by playing against clones in simulated environments, more frequently adopting the strategies that perform best. In this learning process, the algorithm requires little or no external guidance. Once the learning is completed, the algorithm is put to work.
From the antitrust standpoint, the concern is that these autonomous pricing algorithms may independently discover that if they are to make the highest possible profit, they should avoid price wars. That is, they may learn to collude even if they have not been specifically instructed to do so, and even if they do not communicate with one another. This is a problem. First, ‘good performance’ from the sellers’ standpoint, i.e. high prices, is bad for consumers and for economic efficiency. Second, in most countries (including Europe and the US) such ‘tacit’ collusion, not relying on explicit intent and communication, is not currently treated as illegal, on the grounds that it is unlikely to occur among human agents and that, even if it did occur, it would be next to impossible to detect. The conventional wisdom, then, is that aggressive antitrust enforcement would be likely to produce many false positives (i.e. condemning innocent conduct), while tolerant policy would result in relatively few false negatives (i.e. excusing anticompetitive conduct). With the advent of AI pricing, however, the concern is that the balance between the two types of error might be altered. Though no real-world evidence of autonomous algorithmic collusion has been produced so far,1 antitrust agencies are actively debating the problem.2
Those who are concerned (e.g. Ezrachi and Stucke 2015) argue that AI algorithms already outperform humans at many tasks, and there seems to be no reason why pricing should be any different. These commentators refer also to a computer science literature that has documented the emergence of some degree of uncompetitively high prices in simulations where independent pricing algorithms interact repeatedly. Some scholars (e.g. Harrington 2018), are developing paths towards making AI collusion unlawful.
Sceptics counter that these simulations do not use the canonical model of collusion, thus failing to represent actual markets (e.g. Kuhn and Tadelis 2018, Schwalbe 2018).3 Furthermore, the degree of anti-competitive pricing appears to be limited, and in any case high prices as such do not necessarily indicate collusion, which instead must involve some kind of reward-punishment scheme to coordinate firms’ behaviour. According to the sceptics, achieving genuine collusion without communication is a daunting task not only for humans but even for the smartest AI programs, especially when the economic environment is stochastic. Whatever over-pricing is found in the simulations could be due to the algorithms’ failure to learn the competitive equilibrium. If this were so, then there would be little reason to worry, given that the problem will presumably fade away as artificial intelligence develops further.
To inform this policy debate, in a recent paper (Calvano et al. 2018a) we construct AI pricing agents and let them interact repeatedly in controlled environments that reproduce economists’ canonical model of collusion, i.e. a repeated pricing game with simultaneous moves and full price flexibility. Our findings suggest that in this framework even relatively simple pricing algorithms systematically learn to play sophisticated collusive strategies. The strategies mete out punishments that are proportional to the extent of the deviations and are finite in duration, with a gradual return to the pre-deviation prices.
Figure 1 illustrates the punishment strategies that the algorithms autonomously learn to play. Starting from the (collusive) prices on which the algorithms have converged (the grey dotted line), we override one algorithm’s choice (the red line), forcing it to deviate downward to the competitive or Nash price (the orange dotted line) for one period. The other algorithm (the blue line) keeps playing as prescribed by the strategy it has learned. After this exogenous deviation in period , both algorithms regain control of the pricing.
Figure 1 Price Responses to Deviating Price Cut
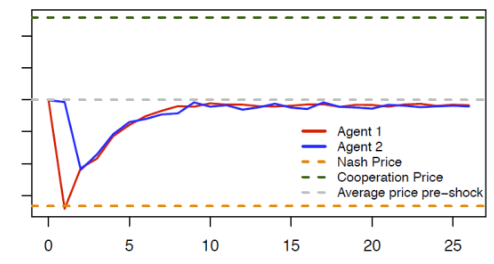
Note: The blue and red lines show the price dynamic over time of two autonomous pricing algorithms (agents) when the red algorithm deviates from the collusive price in the first period.
The figure shows the price path in the subsequent periods. Clearly, the deviation is punished immediately (the blue line price drops immediately after the deviation of the red line), making the deviation unprofitable. However, the punishment is not as harsh as it could be (i.e. reversion to the competitive price), and it is only temporary; afterwards, the algorithms gradually return to their pre-deviation prices.
What is particularly noteworthy is the behaviour of the deviating algorithm. Plainly, it is responding not only to the rival but also to its own action. (If it responded only to the rival, there would be no reason to cut the price in period ,as the rival has charged the collusive price in period .) This kind of self-reactive behaviour is a distinctive sign of genuine collusion, and it would be difficult to explain otherwise.
The collusion that we find is typically partial – the algorithms do not converge to the monopoly price but a somewhat lower one. However, we show that the propensity to collude is stubborn – substantial collusion continues to prevail even when the active firms are three or four in number, when they are asymmetric, and when they operate in a stochastic environment. The experimental literature with human subjects, by contrast, has consistently found that they are practically unable to coordinate without explicit communication save in the simplest case, with two symmetric agents and no uncertainty.
What is most worrying is that the algorithms leave no trace of concerted action – they learn to collude purely by trial and error, with no prior knowledge of the environment in which they operate, without communicating with one another, and without being specifically designed or instructed to collude. This poses a real challenge for competition policy. While more research is needed before considering policy moves, the antitrust agencies’ call for attention would appear to be well grounded.
References and end notes available at the original.


The software engineers are no doubt proud of their handy work. Always the challenge. It dovetails nicely with the overall environment of corruption. Since AI still has no generalized learning algorithm, these cancerous code heads, writing code that will devour the host (and they are part of the host), can not hide behind the “it’s only a tool” cop out. It’s not just a tool, it’s a specific tool. There is clear agency in the design.
>Plainly, it is responding not only to the rival but also to its own action.
I’m confused. Or these guys are idiots. There is no buyer in the description of figure 1, no quantities sold, no nuthin’ that looks like a market?
When the price drops to the orange line, the reaction of most interest is the buyers. Do they shift purchasing almost exclusively to that seller? If so, how does the sluggish blue line drop help the blue line? It loses some money it would have made with the “sticky” customers whilst not competing in the general.
And that doesn’t even get into the fact that “high prices” in non-necessities tend to be seriously self-limiting, unless your algorithm can figure out how to sell “cachet”. :)
There’s a fixed demand curve behind the scenes. Maybe even constant demand, but the existence of a monopoly price suggests a curve.
But you definitely could play this game with constant demand. Example- Everyone buys about the same amount of gasoline each week to get to work, lets say. Vendors still compete on price…
who’s to say that the algorithm cares about the buyers? It’s not written by the buyers, it’s written by the grifters.
Abandon all hope ye sinners
Thy flip phone shall fail
Thy prices shall rise, yea,
Majestically upon the Cloud
Rides the mighty Bezos
Whose algorithm right verily shall
In it’s infinite wisdom
Capture all bright shiny trinkets
within it’s silvery net
And ye, as fishes, flee yet find no shelter
From the All Knowing
The All Seeing Eye
Beware oh Simpleton, ye Perch within
The mirrored Lake
Venture not thee from the weeds!
For Ye Shall Perish!
Know thee that these words are Truth, and
Hide thy fragile bones in what shelter Remains…
Hark! I hear the Robot Dogs on their Grim Journey!
Alight, Poor Soul Alight!
Cachet sells itself. There are some people who prefer to buy at the highest price simply because it is the highest price — because it is the price at which all other buyers are excluded. Paying the highest price maximizes the buyer’s acquisition of what s/he is really after: Veblen’s ‘invidious comparison’. I suppose that such is the principle on which auctions depend, since a great deal of the satisfaction from placing the winning bid comes from realizing that no one else would (or could?) bid so high. In stratified market societies high price serves the purpose of a winnowing basket that separates wheat from chaff. Paying extremely high prices for ‘necessities’ gains one even more admiration than paying high prices for ‘non-necessities’ does, since anybody can pay the proverbial everyday low, low price for subsistence supplies; while nobody wants to be just ‘anybody’.
I agree those sentences are carrying a lot of weight without presenting any of the data to actually support it. All the meat is probably in their full paper, https://cepr.org/active/publications/discussion_papers/dp.php?dpno=13405, but I’m realistically not going to wade through that.
I think this is an interesting result and not really surprising. Independent agents have been known to develop their own communication strategies before, and that’s not even what’s necessarily happening here.
If agent 1 is able to determine some aspects of agent 2’s strategy, then agent 1 could take actions that influence agent 2 to a higher price and lead to a higher equilibrium. This could happen even if agent 2 had a relatively unsophisticated algorithm, so that they aren’t acting in concert.
(Disclaimer: I’m employed by a FAANG, although not in any capacity related to this topic)
If the Nash equilibrium for two or three or four players is not the same as for infinity players, then this is unsurprising.
Is there a good reason to believe 2=infinity? (This is a genuine question–maybe there’s a theorem that says so, even if that seems unlikely to me.)
There are plenty of 2 or 3 player situations. For a great many purchases you don’t have that many choices.
Why would anyone want to model infinity competitors? Markets are finite IRL.
Estimating a quantity asymptotically (i.e. as the number of competitors tends to infinity, in this case) is often easier than computing a corresponding finite quantity exactly. The inexactness makes the problem easier to solve. So, one might model a scenario with a large number of competitors by coming up with an asymptotic estimate and using it as an approximation for a large number of competitors. This sort of modeling is common throughout the sciences.
jeez louise I’m going to go crawl back into my furrow…/s
The whole thing seems to be headed to amazon ruling the world
All Hail Bezos!
The great thing is that no court could prove collusion as those AI devices are almost certainly black boxes and the programmers themselves would not be certain how decisions are made. Not that I want it to happen but I would be curious to see what effect they have on the market over the course of a decade or more as their behaviour starts to ‘drift’ over time. I wonder too if they would be susceptible to chaos theory as well.
It should be assumed they will collude unless explicitly told not to. Algorithms don’t have morality and will exploit all possible angles when solving an optimization problem unless you explicitly forbid some of them or penalize them via the loss function (which isn’t a hard control, as the algorithm might still decide that the benefit outweighs the cost).
Here’s an article about ways that machine learning solutions have found to “cheat” at problems they’ve been assigned. They don’t know they are cheating – they are just exploring all possible options available to them to solve the problem they’ve been given.
That’s strange. I could swear the Supremes ruled back in the ’50s that the tobacco companies were guilty of collaborating even though no evidence of communicating was presented. I may be mistaken, because IANAL, but I remember the case because the discussion said the judges concluded, “Collusion did not require direct communication as in Judge Gary’s ‘little dinners’.” I suppose anti-trust regulators are reluctant to use the precedent. Not to say that nowadays they are all corrupt. I’m sure most of them are honest.
Just more anti-competitive garbage.
I tried to book a hotel a couple of years ago. I would find a decent price and availability, then poked around some more, then went back and the price/availability was gone. The price was higher. And this happened over and over again at different times/days when I looked.
All these ghosts in the machines need to be destroyed.
There are some that do this seemingly as part the process, ie bait and switch. Get this constantly when booking airline reservations. However, there are a couple of very reliable hotel engines where this has never happened and I’ve booked dozens of reservations through them. If I get a price and availability it is always spot on the actual price charged, with no surprises. And I’ve found the user reviews to be extremely credible as well. Certainly I’ve had cases where I delayed booking for many hours and that availability was gone. But I’ve called the actual hotels / B&B’s in a couple of instances and they were booked solid.
Any engine that tries to hide the identity of the property or gives me a site re-direct to book is bad news in my view.
Care to share some of those reliable websites?
Moi against some Artificial Idiocy algos written by people who couldn’t buy a date and throw away half of all farm produce since it is scratch and dent…
this world conquest thingee is going to be much easier than imagined and much much easier than it used to be…
Time to get out from under the fig tree and get back to doing…
That’s not collusion, it’s oligopoly.
The skeptics claiming that collusion won’t take place without communication are showing a serious dearth of imagination. What’s a price but a signal? And who says that it can’t contain more than one message? The trouble with genetic algorithm derived AIs is that they’re black boxes, so if say, a pair of AIs figured out that this particular pricing pattern means “do you want to go higher?” and this other set means “yeah dog” we’d have no way of knowing that communication had taken place.
I recently received a ScAmazon gift card from my nonagenarian mother-in-law, and decided to browse for a book that my local bookseller would have a difficult time getting for me. I looked for the title on my personal ScAmazon log-in, but then remembered that my wife pays for Prime and found the book on her account — a pre-order, $100 list price but with a “coupon” the algo charged $58 with free shipping.
I placed the pre-order through my wife’s account — and three weeks later ScAmazon sent an offer of the same pre-order book to the email associated with my account. The price offered by the ScAmazon algo was $80 plus shipping.
Don’t you just love Dynamic Pricing? Utter B.S.
I was bewildered not having rented for decades by the day-to-day changes in the cost of signing a year-long lease for the same 2bd apartment. And then once you’re locked in, someone else can come in later and pay $200 less a month for the same unit, but the price of mine doesn’t drop. How is that fair? I fumed.
But I guess it’s just the same old law of supply and demand determining prices–only at a rate of change unthinkable before computerization and the internet.
But goddammit I don’t like it. Nor do I like that the prices I am charged are based on MY data that I never gave anyone permission to mine. Talk about insult to injury!
War of the titan algos starts out with one for the buyer and one for the seller. Why not? They slice and dice each other until it escalates to bombs away everywhere. Maybe it takes a while, a long while, say, 1 millionth of a second. Results the same. No human intervention needed except for the suffering.
“According to the sceptics, achieving genuine collusion without communication is a daunting task not only for humans but even for the smartest AI programs, especially when the economic environment is stochastic.”
Define “communication”. Schools of fish turn on a dime, ditto flocks of birds… if “communication” is ‘thinking’ you know another’s intended future behavior as you have just observed some behavior and adjusting [parallelling] it, I’d provisionally disagree with the skeptics. I might say “especially because the economic environment is stochastic” it might be quite the reverse… but opinions differ.
This was inevitable given the churn and flexible pricing of the algo dominated financial markets. How about “lookee-loos” front loading the demand curve? What if the “lookee-loo” traffic is part vendor generated? With old fraud, you had to walk a crooked mile to earn a crooked buck. With computers, you can do this much faster and without effort.
There is no such thing as AI. There is game theory. And there is fixing markets. We add the marketing label “AI” to anything we don’t want questioned.
The next innovation will be digital Marxism. You pay the price you can afford. The poor get discounts, the wealthy pay thousands for a gallon of gas.
It has been a number of years since I read Monopoly Capital, but if memory serves, Sweezy and Baran determined that when competitors fall to as many as 7 or 8 they act as a monopoly without communication. The largest competitor acts as price leader with the others falling in line to maximize profit. Non-price competition then dominates (advertising).
Sounds like AI works similarly. If efficient at profit maximization the number of players that act as a monopoly may go up. Please feel free to correct me if memory is wrong.
I know nothing about this issue but I guess that sales competition is not only affected by only one item but many. I am thinking that a vast majority of buyers are constrained by disposable income limits. If there is collusion in every item, what happens next? Less items are sold?
Most of these vendor platforms know who you are and what you spend your money on and how often. As such, they will know that you are prepared to pay more for your item, flight or hotel than the guy who lives next door to you.
You will need to take steps to not get fleeced when you buy online.
Mac users, IIRC, are presented with higher-priced airline tickets by Expedia, etc.
By 2024, it’ll be illegal for friends and family to use each others’ online shopping accounts in order to get fair prices — all to keep us safe from ‘identity theft’, you see.
And there will be glowing headlines like, “Heroic FBI Raid Nabs Counterfeit Identity Ring”.
ALEC is probably drafting the text of the law right now. . .
Reminds me of Marshall Wace and their excellent mechanism for laundering insider trading tips.
Given the proportion of trades in financial markets made by HFT AIs, one might assume a high pricing effect overall, then? Supercomputers on Wall Street are sure to figure out a bubble is good for all of them.
It happens with humans too, though: in this country (NZ) landlords aren’t supposed to charge “above market” rents, but they manage very well to all raise their rents gradually, together, and across the board (yet quicker than wage inflation, of course!), so no individual can be accused of price gouging or monopolistic behaviour or collusion.
Given the instant access to pricing that all economic actors have now, we witness the phenomenon of generalized, or total, monopoly.
economists’ canonical model of collusion
“canonical” !!
The framing here seems almost designed for public policy impotence.
I’ve found a large, dominant ticket selling site to have an extremely accurate algo for moving tickets as a seller. If I set the price too far above the recommended setting they will sit forever, too low and they go almost immediately. This is actually pretty handy based on your time horizon, although they change constantly so you have to monitor it if you are selling over a long period of time. And profit as a seller has zero to do with it, that is all about the demand for the event and actual cost.
The psychology and management of herds.
This is the one of the best articles I’ve read here!