Yves here. It may seem odd for Michael Olenick, who has lambasted Wikipedia at NC and later at the Institute for New Economic Thinking, to suggest that a Wikipedia offspring, a heretofore half-hearted search engine project that he proposes calling Wikisearch, could serve as a badly-needed competitor for Google. But we live in a world of beauty contests between Cinderella’s ugly sisters.
It’s no secret that Google has become so terrible that it’s unusable for anything but shopping. Not only no more Boolean searches, but you can’t even to “Verbatim” and an exact date range at the same time. And these are supposed to be tech wunderkind?
By Michael Olenick, Executive Fellow, INSEAD Business School. Originally published at Blue Ocean Thinking
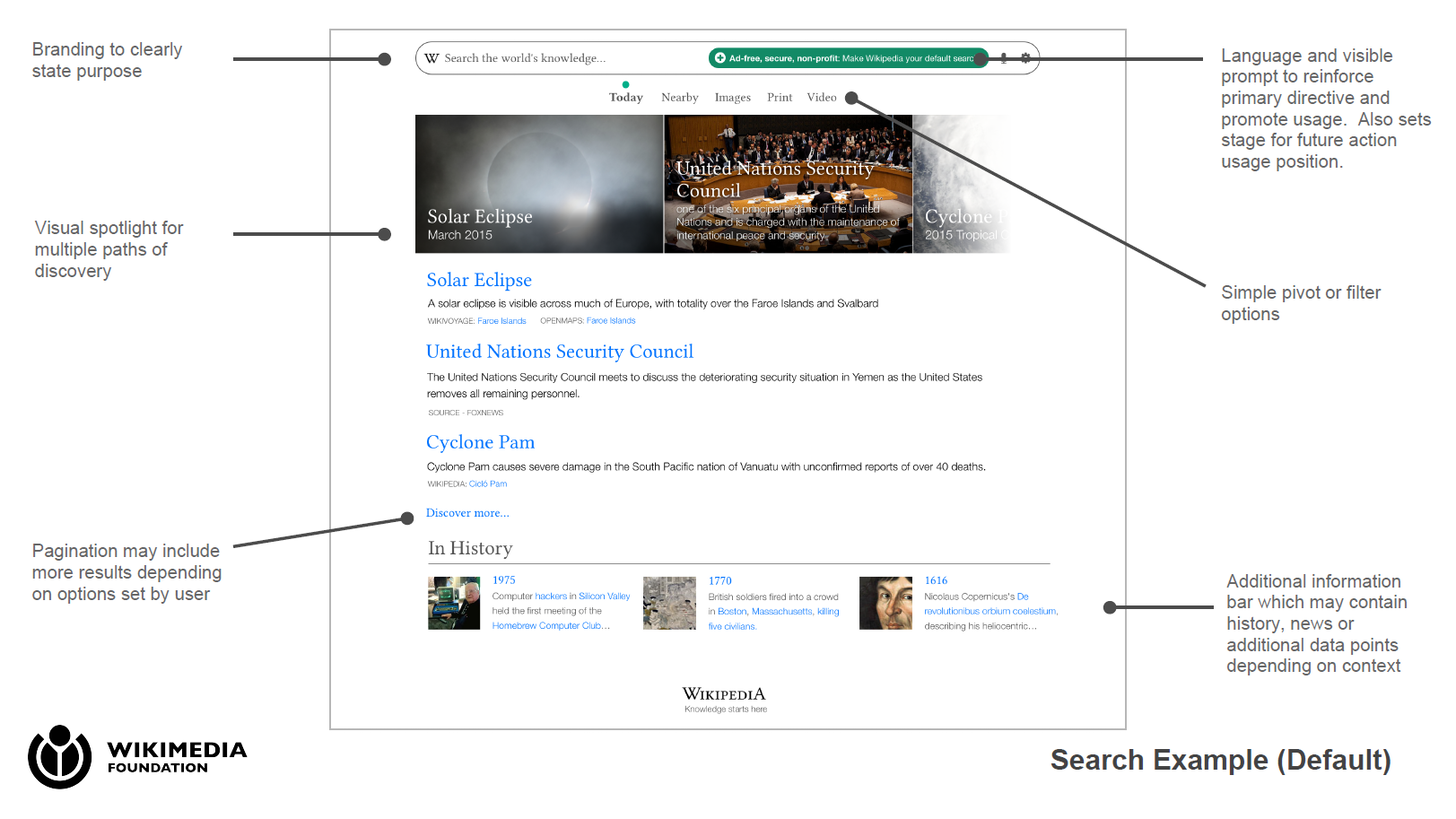
I’ve been focused on Wikipedia lately, after my article published by the Institute of New Economic Thinking, INET, Wikipedia’s Ties to Big Tech, here
That put me in touch with lots of senior Wikipedia people, past and present. None of them are Wikimedia people who, as I’ve mentioned, repeatedly ignored questions. Before my article, they asked me to submit them by email then proceeded to entirely blow them off, transparency apparently being more aspirational than operational. After publication, Jimmy Wales responded with a not-so-small freakout that he’d never said something he had indeed said, in writing, that was quoted in the same article.
Still, that article led me to virtually meet some interesting and clearly very smart past and present senior Wikipedia editors, people who know Wikipedia and Wikimedia well.
Some definitions are needed. Wikipedia is the website we know and sometimes love, the sprawling “encyclopedia” that’s virtually always the first or second term after entering a noun into Google. Wikimedia is the parent non-profit that owns Wikipedia. Repeating the financials of my first story, Wikimedia has at least $180 million in reserves plus another $90 million in an “endowment” held by the non-profit Tides Foundation. There’s lots more to this and I’d urge anybody reading this to read the INET article if you haven’t already.
The people who write and maintain the various Wikipedia websites — each language has its own — is a group of volunteers collectively referred to as “the community.” Individual community members are informally called Wikipedians, a common enough term my spell checker knows it. Little of the almost $300 million pot of gold Wikimedia has collected from donations flows to Wikipedians.
Speaking with the longer-term Wikipedians, one element that came up repeatedly is a turning point in Wikipedia’s history when the firm decided to create a Knowledge Engine. That’s a project cooked up by former Wikimedia head Lila Tretikov. It looks like a search engine probably because that’s exactly what it clearly was.
Consistent with the type of transparency I’ve seen, Lila and Wikipedia co-founder and figurehead Jimmy Wales not only kept the project secret but repeatedly obfuscated it to the community. That’s a bad idea in any organization, a worse idea in a non-profit, a terrible idea in a non-profit that sets transparency as a core operating principle, and a godawful inexcusably horrible idea in a non-profit where a not-so-small army of volunteers create 100% of the product that anybody cares about.
Lila secretly applied for and received a grant from the Knight Foundation, first asking for millions then, after being rejected, less. They were eventually granted $250,000 to create a study. As that progressed, the entire project came to light. The two apparently lied that the grant application was secret, due to donor privacy, until a Wikipedian contacted Knight who clarified not only wasn’t it secret but they preferred it to be out in the open. When the lies became clear, much drama ensued as both community members and Wikimedia employees felt betrayed.
Compounding an already bad situation is a feeling I’ve heard repeatedly that Lila picked up people management skills in her native USSR with a more authoritarian tone than many were accustomed to. After a number of defections at both Wikimedia and Wikipedia, Lila resigned with a golden parachute on February 25, 2016 effective March. Shortly before, in January 2016, Jimmy set out to create an endowment to raise $100 million, an amount that seems like it’d be a good start for a limited specialized search engine.
In Lila’s place, Wikimedia promoted then head of public relations Katherine Maher to the top job. Maher has an NYU degree in Middle Eastern and Islamic studies she earned in 2005. After that, she worked with the UN, HSBC bank, wrote about the Arab Spring, and interned at the Council of Foreign Relations where she remains a life member. Somehow, those jobs prepared her for a job as head of PR then CEO at Wikimedia less than a decade after graduation. In an odd coincidence, Maher was introduced to the Wikimedia staff at the same meeting where Tretikov was announced as the new executive director. Maher appeared to be visibly more comfortable.
Fast forward five years. Today, April 15, 2021, is Maher’s last day. Wales’ endowment, which Wikimedia promised to move to a separate charity from Tides when it reached $33 million, is near or past its $100 million goal and remains at Tides. Questions about the endowment were met with “we’ll get back to you” then, days later, crickets. Finally, there’s a new for-profit Wikimedia Enterprise offering to streamline data feeds to Big Tech because Google, the undisputed king of parsing web pages, apparently needs help electronically reading Wikipedia pages.
This last point cross-references to something Wikimedia’s new CTO, Grant Ingersoll, said in their open house a couple weeks ago when discussing Wikipedia Enterprise … he’s never talked to Google, Apple, or Amazon about the offering. Lane Becker, head of the project, also said he’s never spoken to them about their needs or how much they’d be willing to pay. As I’ve pointed out, Wikimedia has repeatedly refused to answer questions about how much time staffers are spending supporting Big Tech. Wired Magazine wrote “point people” are in discussions with Big Tech, which is the opposite of what the point people said when asked. It’s almost like Wired’s information came from a public relations firm rather than from people tasked with doing the work. You’d almost think press releases are being “rebranded” as news, an idea that once upon a time would’ve repulsed reporters.
Obviously, Google is more than able to electronically read the web, Wikipedia and all the rest. Google needs help reading and parsing Wikipedia pages like Simone Bilesneeds help walking a balance beam. Amazon and Apple aren’t far behind. There is no strain at all on Wikipedia’s servers as evidenced by the low web hosting fees Wikimedia pays (about $2.4 million/year to host a top-ten website). Coupled with the blank stares from those in the know I’m going to take a wild guess about how much Wikimedia pays supporting Google, Amazon, Apple, and the rest… nothing, or close to it.
I’m sure there’s some collaboration: hallway conversations at conventions, informal meetings … maybe the occasional lunch in San Francisco. But I don’t think there is any substantive work, any genuine drag on Wikimedia resources.
However, I do think the idea that there is work, a substantive out-of-pocket subsidy, is a great motivator to enrage and rally the community. They could, would, and should demand that Wikimedia not subsidize Google, Amazon, and Apple. The idea that very rich Big Tech is making seemingly small Wikimedia subsidize them is a good way to rally up Wikipedians. Except I’m pretty sure it’s nonsense. It’s Wikimedia that’s arguably taking advantage of the Wikipedians by creating an enormous cash hoard. Google and the rest just get the fruits of that arrangement; they’re freeloaders, not leaches.
This leads me to a conclusion I suspect will be unpopular: maybe Wikimedia should create Jimmy and Lila’s search engine assuming they’re not already doing so. Instead of a Google killer it’d return 10-20 accurate, relevant hand-curated results for the more common searches. A googol, that Google takes their names from, is a one with 100 zeros after it, the number of pages Google hoped to eventually read and index. But what if the vast majority of those results aren’t all that applicable to the mass of searchers? What if, instead, that enormous number of pages actually gets in the way of more casual searchers? What if a vastly smaller number of hand-cultivated pages was better for the vast majority of searchers?
And, of course, it’s obvious that Wikipedia — with the content, community of content builders, links to various external interesting articles, userbase, and brand — could release an offering exactly like that at far lower development costs than anybody else. Leading to the question of why shouldn’t Wikimedia/pedia create a search engine where the top result for any noun is either the noun’s webpage, if they have one, the second page is Wikipedia, and the next two pages are hand-curated high-quality open-content websites? Do we really need the vast majority of searches to return hundreds of millions of results? Quoting Monty Python, “What’s wrong with a kiss, boy, hmm?” Oftentimes, less is more.
Would this satisfy every search? No, and it shouldn’t. It should produce a small number of good results, arguably as good or better than Google, for the vast majority of common searches. Would it work for me, a professional researcher? No. But most noncustomers aren’t professional or even amateur researchers; they just want some basic, easy to understand information.
Ironically, there was a search engine like that way back when the web first launched, Yahoo. It was a hand-curated listing of web pages and, difficult as it is to believe now, it one day ruled the web. Eventually, the yahoos at Yahoo decided to professionalize and the company hired Hollywood hacks who promptly burnt the place to the ground. They charged sites to be listed in the directory and, not long after, let them bid their way to the top. This eroded credibility, search quality, and eventually the ability of Yahoo search to provide meaningful value.
Interestingly, the strategy that obliterated Yahoo isn’t all that different than Google’s current strategy. They frequently fill top results with ads and internal links to other parts of Google. A notable exception is the ever-present link to Wikipedia which, conveniently for Google, doesn’t support a competing ad platform to lure advertisers to eyeballs beyond Google’s reach.
Obviously, if WikiSearch didn’t answer what a person was looking for they could failover to Google, which is largely how Google got its start at Yahoo in the first place. And, just as obviously, Google would pay for the placement, possibly more money than Wikimedia takes in altogether for that service alone. But, with the hand-curated results, most people wouldn’t need to failover. They’d get what they’d need curated by regular intelligence, not the artificial flavor.
What about gaming the system to manipulate results? Like I wrote in my original article, Wikipedia manipulation is a very real problem. Undisclosed conflicts of interest and state actors are especially troubling in addition to the secretly paid editors and self-promoting blowhards. Then again, Google has the same problem. There’s a whole army of “search engine optimization” specialists who exist to game Google search results. Wikipedia at least pays lip service that these behaviors are unacceptable whereas Google outright supports them by allowing them to run advertisements.
The idea that Lila and Jimmy may have been on to something worthwhile is anathema to most Wikipedians and, honestly, it doesn’t sit well with me either. I don’t know Lila but, in my experience, Jimmy’s a jerk with his baseless ad hominem attacks. Still, obnoxious narcissists are sometimes right and this might be one of those times. Maybe WikiSearch would be a good strategic move to challenge Google’s dominance in search.
Would Google mind that? I’m not sure. On one hand, if WikiSearch went well it might give them breathing room against antitrust regulators focused on their current search monopoly. On the other, a genuine competitor that takes meaningful traffic might not be what they had in mind. There’s a chance for a classic disruptive move: the barely good enough offering that eventually comes to dominate and overtake the high-cost incumbent.
Finally, there’s the ethics of the whole thing. WikiSearch is only possible with more Wikipedians spinning the gerbil wheel for free while vast amounts of Wikimedia money piles up in reserve accounts. Wikimedia argues they can’t collect too much from for-pay businesses because of charity rules but this is nonsense: plenty of charities are dominated by single donors (we’re looking at you, Firefox). They’d just need their accountants and lawyers to do that voodoo they do so well.


The Library of Congress always seemed to me like a logical umbrella under which to build out a public search and internet archive system which could be quite simply legally constrained from data mining and commercially distorted results. The data centers are already there, just needing to be converted from unconstitutional dragnet surveillance to useful and legal purposes.
What’s the point of this? As the author observes, Wikipedia is seriously conflicted and untrustworthy. Students who rely on it to write essays are (or should be) penalized. Why would any researcher trust Wikipedia/Wikimedia to provide “hand-curated” search results?
Is there something wrong with Duck Duck, or the other google alternatives?
I disagree. No student should be punished for using it as long as they verify references.
Wiki, like many sites, is only as good as its references.
Penalizing any student for using any site due to it’s sometimes questionable material is ridiculous.
I 100% agree about Wikipedia but, as Yves put it, there’s not a whole lot that can credibly challenge Google. Outgoing (well, not gone) Wikimedia head Katherine Maher was just on The Daily Show and smiled and nodded when Trevor said “the downside (of being non-profit) is you often struggle to have enough money to keep Wikipedia running…” which is total nonsense. They have almost $300 million banked. Neither Trevor or Katherine mentioned the wife of the owner of their PR firm is a long-time Daily Show employee. Their ethics suck.
Still … they’re not Google. And .. that’s it. That’s my entire justification. My thought is if a search engine, any search engine, gained steam then somebody might come along and make one that isn’t all ads and internal links.
Duck Duck is Bing and, you know the saying, if you’re not paying then you’re the product. I’m not sure how they’re making money but I am sure they either are or have a plan to.
In a perfect world, somebody would branch and mirror Wikipedia and turn it into a search engine with controls for conflict and quality. But a Wikipedia search engine would be a start that, maybe (maybe…) would get something else to gain some traction.
Government should’ve broken up and should break up these monopolies but we can’t just sit around and wait because, let’s face it, there’s not much smoke much less fire from antitrust regulators.
I like some of the functions that Cirrus search has, like the ability to search inside templates. You can find all the entries Naked Capitalism is linked from pretty quickly.
There’s another app I’ve seen mentioned, which extracts the blue-links and references and strips away the wikiwikiprose: e.g. Tides Foundation (§), which shows that just over half of the out-going links are https, among other things.
Your idea is intriguing.
> What’s the point of this?
Better search, along with better search principles (the original citation analysis in the early Google).
If a Wikipedia search engine went one hop out from the references embedded in the Notes, it would provide an excellent point of entry for real (re)search, as opposed to a million pages of crap, from which Google can’t even weed out the dupes, polluted by SEO optimizers.
Of course the SEO optimizers would attempt to infest Wikipedia (more than the already do). Preventing that would be an ongoing cost.
While this article is wildly insightful and spot-on accurate in many places, I do wonder how many regular folks would actually agree with the premise, “It’s no secret that Google has become so terrible that it’s unusable for anything but shopping. Not only no more Boolean searches…”
Google is still highly usable for a wide array of needs, and (maybe I’m special, but) I’m still able to complete Boolean searches by using search operators. Can someone explain what the author meant here?
You must not talk to many writers or researchers. Every academic I know, for starters, found Google circa 2009 to be a great tool and finds the current incarnation to be nearly useless. The prioritization of recency and the emphasis on authoritative sites has simply killed finding many pieces. I can literally put in a search string from an article I cut and pasted (where I stupidly didn’t put in the link) from my archives and Google can’t find it. That’s a total fail.
You can’t do anything remotely like the old “advanced search” which made it easy to do very complicated Boolean searches. The “-” does not work and you can’t do date ranges plus verbatim.
Curated search services (not ‘engines’) have been tried in the past, and apparently didn’t go over very well, or I would think they’d be with us today. Getting Wikipedia to do it — presumably with donated labor — does not seem promising, especially if you’ve contributed anything to Wikipedia and run into their culture and manners. I think there in a problem inherent in centralized server-client relationships that tends to push such systems toward domination and exploitation, i.e. capitalism. There is a possibility of building something more distributed and anarchic, like Gnutella, I suppose, where the goods to be targeted would be information in general rather than MP3s, and the searching work distributed throughout a cooperating P2P network, but there would be many difficult problems to be solved on the way. I’ll set to work immediately….
> Curated search services (not ‘engines’) have been tried in the past, and apparently didn’t go over very well,
Not so. LexisNexis and allied search engines work very well in verticals, and you pay for them. The issue is getting the owners of the search engine not to be as stupid as Yahoo, or as evil as Google. Perhaps Jimmy Wales can rise to the occasion.
I do know that Wikipedia, unlike Google, doesn’t make my skin crawl. There’s something to be said for that.
“I do know that Wikipedia, unlike Google, doesn’t make my skin crawl.”
Who decides what is a “Reliable Source”? It is usually the corporate or Western state owned media, but it can be anything the Wikilords choose, without explanation. Creepy.
Somewhat feasible.
Need a natural language database for searching.
Do you have any IBM Contacts? Their STAIRS product would be an excellent foundation. It is written assembler, so the logic and source code for the database might be somewhere.
Reverse engineer to a modern programming language and that’s the database.
Link STAIRS
Note that Wikimedia is building something called Wikifunctions, or Abstract Wikipedia. From the relevant page on Wikimedia’s Meta wiki:
This project consists of two parts: Abstract Wikipedia and Wikifunctions.
The goal of Abstract Wikipedia is to let more people share more knowledge in more languages. Abstract Wikipedia is a conceptual extension of Wikidata.[2] In Abstract Wikipedia, people can create and maintain Wikipedia articles in a language-independent way. A Wikipedia in a language can translate this language-independent article into its language. Code does the translation.
Wikifunctions is a new Wikimedia project that allows anyone to create and maintain code. This is useful in many different ways. It provides a catalog of all kinds of functions that anyone can call, write, maintain, and use. It also provides code that translates the language-independent article from Abstract Wikipedia into the language of a Wikipedia. This allows everyone to read the article in their language. Wikifunctions will use knowledge about words and entities from Wikidata.
This will get us closer to a world where everyone can share in the sum of all knowledge.
More here: https://meta.wikimedia.org/wiki/Abstract_Wikipedia
This will also be a multilingual “knowledge engine” of sorts.
Wikidata does seem to be what the WMF is most excited about, as you’ve documented for a while now. This is an overview scan of Wikidata, showing that humans create 35% of the WD items, and are responsible for 42% of the contributions.
There are currently 59 human and 3 bot admins on WD (see the sidebar), as opposed to over a thousand sysops on English Wikipedia. There are, perhaps unsurprisingly, far fewer blocks on the former (§) than on the latter (§).