This is Naked Capitalism fundraising week. 735 donors have already invested in our efforts to combat corruption and predatory conduct, particularly in the financial realm. Please join us and participate via our donation page, which shows how to give via check, credit card, debit card, PayPal, Clover, or Wise. Read about why we’re doing this fundraiser, what we’ve accomplished in the last year, and our current goal, supporting our expanded daily Links
Yves here. This is a devastating, must-read paper by Servaas Storm on how AI is failing to meet core, repeatedly hyped performance promises, and never can, irrespective of how much money and computing power is thrown at it. Yet AI, which Storm calls “Artificial Information” is still garnering worse-than-dot-com-frenzy valuations even as errors are if anything increasing.
By Servaas Storm, Senior Lecturer of Economics, Delft University of Technology. Originally published at the Institute for New Economic Thinking website
This paper argues that (i) we have reached “peak GenAI” in terms of current Large Language Models (LLMs); scaling (building more data centers and using more chips) will not take us further to the goal of “Artificial General Intelligence” (AGI); returns are diminishing rapidly; (ii) the AI-LLM industry and the larger U.S. economy are experiencing a speculative bubble, which is about to burst.
The U.S. is undergoing an extraordinary AI-fueled economic boom: The stock market is soaring thanks to exceptionally high valuations of AI-related tech firms, which are fueling economic growth by the hundreds of billions of U.S. dollars they are spending on data centers and other AI infrastructure. The AI investment boom is based on the belief that AI will make workers and firms significantly more productive, which will in turn boost corporate profits to unprecedented levels. But the summer of 2025 did not bring good news for enthusiasts of generative Artificial Intelligence (GenAI) who were all hyped up by the inflated promise of the likes of OpenAI’s Sam Altman that “Artificial General Intelligence” (AGI), the holy grail of current AI research, would be right around the corner.
Let us more closely consider the hype. Already in January 2025, Altman wrote that “we are now confident we know how to build AGI”. Altman’s optimism echoed claims by OpenAI’s partner and major financial backer Microsoft, which had put out a paper in 2023 claiming that the GPT-4 model already exhibited “sparks of AGI.” Elon Musk (in 2024) was equally confident that the Grok model developed by his company xAI would reach AGI, an intelligence “smarter than the smartest human being”, probably by 2025 or at least by 2026. Meta CEO Mark Zuckerberg said that his company was committed to “building full general intelligence”, and that super-intelligence is now “in sight”. Likewise, Dario Amodei, co-founder and CEO of Anthropic, said “powerful AI”, i.e., smarter than a Nobel Prize winner in any field, could come as early as 2026, and usher in a new age of health and abundance — the U.S. would become a “country of geniuses in a datacenter”, if ….. AI didn’t wind up killing us all.
For Mr. Musk and his GenAI fellow travelers, the biggest hurdle on the road to AGI is the lack of computing power (installed in data centers) to train AI bots, which, in turn, is due to a lack of sufficiently advanced computer chips. The demand for more data and more data-crunching capabilities will require about $3 trillion in capital just by 2028, in the estimation of Morgan Stanley. That would exceed the capacity of the global credit and derivative securities markets. Spurred by the imperative to win the AI-race with China, the GenAI propagandists firmly believe that the U.S. can be put on the yellow brick road to the Emerald City of AGI by building more data centers faster (an unmistakenly “accelerationist” expression).
Interestingly, AGI is an ill-defined notion, and perhaps more of a marketing concept used by AI promotors to persuade their financiers to invest in their endeavors. Roughly, the idea is that an AGI model can generalize beyond specific examples found in its training data, similar to how some human beings can do almost any kind of work after having been shown a few examples of how to do a task, by learning from experience and changing methods when needed. AGI bots will be capable of outsmarting human beings, creating new scientific ideas, and doing innovative as well as all of routine coding. AI bots will be telling us how to develop new medicines to cure cancer, fix global warming, drive our cars and grow our genetically modified crops. Hence, in a radical bout of creative destruction, AGI would transform not just the economy and the workplace, but also systems of health care, energy, agriculture, communications, entertainment, transportation, R&D, innovation and science.
OpenAI’s Altman boasted that AGI can “discover new science,” because “I think we’ve cracked reasoning in the models,” adding that “we’ve a long way to go.” He “think[s] we know what to do,” saying that OpenAI’s o3 model “is already pretty smart,” and that he’s heard people say “wow, this is like a good PhD.” Announcing the launch of ChatGPT-5 in August, Mr. Altman posted on the internet that “We think you will love using GPT-5 much more than any previous Al. It is useful, it is smart, it is fast [and] intuitive. With GPT-5 now, it’s like talking to an expert — a legitimate PhD level expert in anything any area you need on demand, they can help you with whatever your goals are.”
But then things began to fall apart, and rather quickly so.
ChatGPT-5 Is a Letdown
The first piece of bad news is that much-hyped ChatGPT-5 turned out to be a dud — incremental improvements wrapped in a routing architecture, nowhere near the breakthrough to AGI that Sam Altman had promised. Users are underwhelmed. As the MIT Technology Review reports: “The much-hyped release makes several enhancements to the ChatGPT user experience. But it’s still far short of AGI.” Worryingly, OpenAI’s internal tests show GPT-5 ‘hallucinates’ in circa one in 10 responses of the time on certain factual tasks, when connected to the internet. However, without web-browsing access, GPT-5 is wrong in almost 1 in 2 responses, which should be troublesome. Even more worrisome, ‘hallucinations’ may also reflect biases buried within datasets. For instance, an LLM might ‘hallucinate’ crime statistics that align with racial or political biases simply because it has learned from biased data.
Of note here is that AI chatbots can be and are actively used to spread misinformation (see here and here). According to recent research, chatbots spread false claims when prompted with questions about controversial news topics 35% of the time — almost double the 18% rate of a year ago (here). AI curates, orders, presents, and censors information, influencing interpretation and debate, while pushing dominant (average or preferred) viewpoints while suppressing alternatives, quietly removing inconvenient facts or making up convenient ones. The key issue is: Who controls the algorithms? Who sets the rules for the tech bros? It is evident that by making it easy to spread “realistic-looking” misinformation and biases and/or suppress critical evidence or argumentation, GenAI does and will have non-negligible societal costs and risks — which have to be counted when assessing its impacts.
Building Larger LLMs Is Leading Nowhere
The ChatGPT-5 episode raises serious doubts and existential questions about whether the GenAI industry’s core strategy of building ever-larger models on ever-larger data distributions has already hit a wall. Critics, including cognitive scientist Gary Marcus (here and here), have long argued that simply scaling up LLMs will not lead to AGI, and GPT-5’s sorry stumbles do validate those concerns. It is becoming more widely understood that LLMs are not constructed on proper and robust world models, but instead are built to autocomplete, based on sophisticated pattern-matching — which is why, for example, they still cannot even play chess reliably and continue to make mind-boggling errors with startling regularity.
My new INET Working Paper discusses three sobering research studies showing that novel ever-larger GenAI models do not become better, but worse, and do not reason, but rather parrot reasoning-like text. To illustrate, a recent paper by scientists at MIT and Harvard shows that even when trained on all of physics, LLMs fail to uncover even the existing generalized and universal physical principles underlying their training data. Specifically, Vafa et al. (2025) note that LLMs that follow a “Kepler-esque” approach: they can successfully predict the next position in a planet’s orbit, but fail to find the underlying explanation of Newton’s Law of Gravity (see here). Instead, they resort to fitting made-up rules, that allow them to successfully predict the planet’s next orbital position, but these models fail to find the force vector at the heart of Newton’s insight. The MIT-Harvard paper is explained in this video. LLMs cannot and do not infer physical laws from their training data. Remarkably, they cannot even identify the relevant information from the internet. Instead, they make it up.
Worse, AI bots are incentivized to guess (and give an incorrect response) rather than admit they do not know something. This problem is recognized by researchers from OpenAI in a recent paper. Guessing is rewarded — because, who knows, it might be right. The error is at present uncorrectable. Accordingly, it might well be prudent to think of “Artificial Information” rather than “Artificial Intelligence” when using the acronym AI. The bottom line is straightforward: this is very bad news for anyone hoping that further scaling — building ever larger LLMs — would lead to better outcomes (see also Che 2025).
95% of Generative AI Pilot Projects in Companies Are Failing
Corporations had rushed to announce AI investments or claim AI capabilities for their products in the hope of turbocharging their share prices. Then came the news that the AI tools are not doing what they are supposed to do and that people are realizing it (see Ed Zitron). An August 2025 report titled The GenAI Divide: State of AI in Business 2025, published by MIT’s NANDA initiative, concludes that 95% of generative AI pilot projects in companies are failing to raise revenue growth. As reported by Fortune, “generic tools like ChatGPT [….] stall in enterprise use since they don’t learn from or adapt to workflows”. Quite.
Indeed, firms are backpedaling after cutting hundreds of jobs and replacing these by AI. For instance, Swedish “Buy Burritos Now, Pay Later” Klarna bragged in March 2024 that its AI assistant was doing the work of (laid-off) 700 workers, only to rehire them (sadly, as gig workers) in the summer of 2025 (see here). Other examples include IBM, forced to reemploy staff after laying off about 8,000 workers to implement automation (here). Recent U.S. Census Bureau data by firm size show that AI adoption has been declining among companies with more than 250 employees.
MIT economist Daren Acemoglu (2025) predicts rather modest productivity impacts of AI in the next 10 years and warns that some applications of AI may have negative social value. “We’re still going to have journalists, we’re still going to have financial analysts, we’re still going to have HR employees,” Acemoglu says. “It’s going to impact a bunch of office jobs that are about data summary, visual matching, pattern recognition, etc. And those are essentially about 5% of the economy.” Similarly, using two large-scale AI adoption surveys (late 2023 and 2024) covering 11 exposed occupations (25,000 workers in 7,000 workplaces) in Denmark, Anders Humlum and Emilie Vestergaard (2025) show, in a recent NBER Working Paper, that the economic impacts of GenAI adoption are minimal: “AI chatbots have had no significant impact on earnings or recorded hours in any occupation, with confidence intervals ruling out effects larger than 1%. Modest productivity gains (average time savings of 3%), combined with weak wage pass-through, help explain these limited labor market effects.” These findings provide a much-needed reality check for the hyperbole that GenAI is coming for all of our jobs. Reality is not even close.
GenAI will not even make tech workers who do the coding redundant, contrary to the prediction by AI enthusiasts. OpenAI researchers have found (in early 2025) that advanced AI models (including GPT-4o and Anthropic’s Claude 3.5 Sonnet) still are no match for human coders. The AI bots failed to grasp how widespread bugs are or to understand their context, leading to solutions that are incorrect or insufficiently comprehensive. Another new study from the nonprofit Model Evaluation and Threat Research (METR) finds that in practice, programmers, using early 2025-AI-tools, are actually slower when using AI assistance tools, spending 19 percent more time when using GenAI than when actively coding by themselves (see here). Programmers spent their time on reviewing AI outputs, prompting AI systems, and correcting AI-generated code.
The U.S. Economy at Large Is Hallucinating
The disappointing rollout of ChatGPT-5 raises doubts about OpenAI’s ability to build and market consumer products that users are willing to pay for. But the point I want to make is not just about OpenAI: the American AI industry as a whole has been built on the premise that AGI is just around the corner. All that is needed is sufficient “compute”, i.e., millions of Nvidia AI GPUs, enough data centers and sufficient cheap electricity to do the massive statistical pattern mapping needed to generate (a semblance of) “intelligence”. This, in turn, means that “scaling” (investing billions of U.S. dollars in chips and data centers) is the one-and-only way forward — and this is exactly what the tech firms, Silicon Valley venture capitalists and Wall Street financiers are good at: mobilizing and spending funds, this time for “scaling-up” generative AI and building data centers to support all the expected future demand for AI use.
During 2024 and 2025, Big Tech firms invested a staggering $750 billion in data centers in cumulative terms and they plan to roll out a cumulative investment of $3 trillion in data centers during 2026-2029 (Thornhill 2025). The so-called “Magnificent 7” (Alphabet, Apple, Amazon, Meta, Microsoft, Nvidia, and Tesla) spent more than $100 billion on data centers in the second quarter of 2025; Figure 1 gives the capital expenditures for four of the seven corporations.
FIGURE 1
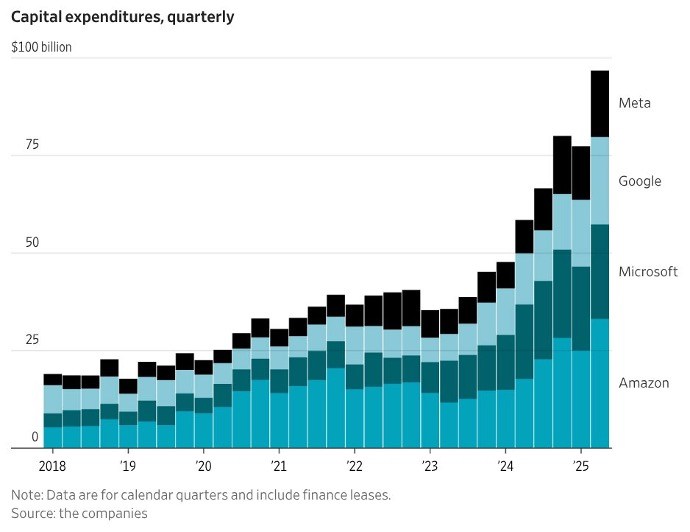
Christopher Mims (2025), https://x.com/mims/status/1951…
The surge in corporate investment in “information processing equipment” is huge. According to Torsten Sløk, chief economist at Apollo Global Management, data center investments’ contribution to (sluggish) real U.S. GDP growth has been the same as consumer spending over the first half of 2025 (Figure 2). Financial investor Paul Kedrosky finds that capital expenditures on AI data centers (in 2025) have passed the peak of telecom spending during the dot-com bubble (of 1995-2000).
FIGURE 2
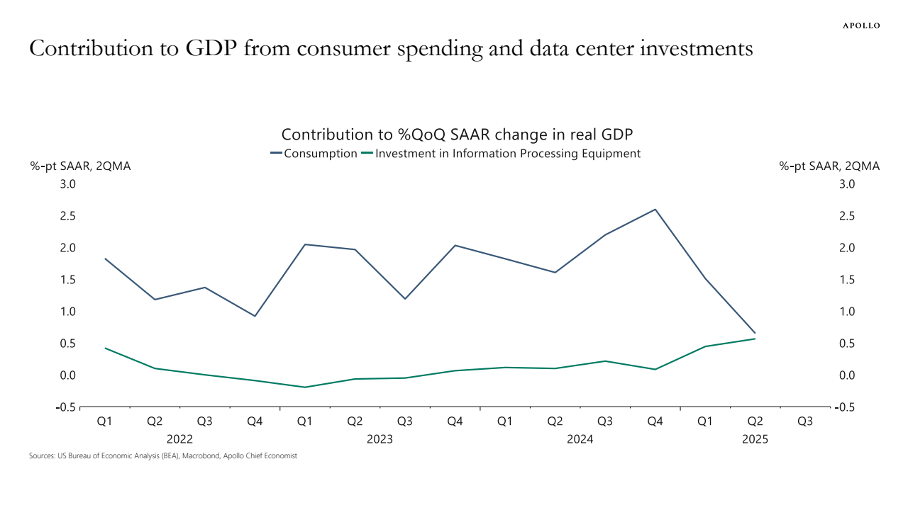
Source: Torsten Sløk (2025). https://www.apolloacademy.com/…
Following the AI hype and hyperbole, tech stocks have gone through the roof. The S&P500 Index rose by circa 58% during 2023-2024, driven mostly by the growth of the share prices of the Magnificent Seven. The weighted-average share price of these seven corporations increased by 156% during 2023-2024, while the other 493 firms experienced an average increase in their share prices of just 25%. America’s stock market is largely AI-driven.
Nvidia’s shares rose by more than 280% over the past two years amid the exploding demand for its GPUs coming from the AI firms; as one of the most high-profile beneficiaries of the insatiable demand for GenAI, Nvidia now has a market capitalization of more than $4 trillion, which is the highest valuation ever recorded for a publicly traded company. Does this valuation make sense? Nvidia’s price-earnings (P/E) ratio peaked at 234 in July 2023 and has since declined to 47.6 in September 2025 — which is still historically very high (see Figure 3). Nvidia is selling its GPUs to neocloud companies (such as CoreWeave, Lambda, and Nebius), which are funded by credit, from Goldman Sachs, JPMorgan, Blackstone and other Wall Street private equity firms, collateralized by the data centers filled with GPUs. In key cases, as explained by Ed Zitron, Nvidia offered the neocloud companies, which are loss making, to buy unsold cloud compute worth billions of U.S. dollars, effectively backstopping its clients — all in the expectation of an AI revolution that still has to arrive.
Likewise, the share price of Oracle Corp. (which is not included in the “Magnificent 7”) rose by more than 130% during mid-May and early September 2025 following the announcement of its $300 billion cloud-computing infrastructure deal with OpenAI. Oracle’s P/E ratio shot up to almost 68, which means that financial investors are willing to pay almost $68 for $1 of Oracle’s future earnings. One obvious problem with this deal is that OpenAI doesn’t have $300 billion; the company made a loss of $15 billion during 2023-2025 and is projected to make a further cumulative loss of $28 billion during 2026-2028 (see below). It is unclear and uncertain where OpenAI will get the money from. Ominously, Oracle needs to build the infrastructure for OpenAI before it can collect any revenue. If OpenAI cannot pay for the enormous computing capacity it agreed to buy from Oracle, which seems likely, Oracle will be left with the expensive AI infrastructure, for which it may not be able to find alternative customers, especially once the AI bubble fizzles out.
Tech stocks thus are considerably overvalued. Torsten Sløk, chief economist at Apollo Global Management, warned (in July 2025) that AI stocks are even more overvalued than dot-com stocks were in 1999. In a blogpost, he illustrates how P/E ratios of Nvidia, Microsoft and eight other tech companies are higher than during the dot-com era (see Figure 3). We all remember how the dot-com bubble ended — and hence Sløk is right in sounding the alarm over the apparent market mania, driven by the “Magnificent 7” that are all heavily invested in the AI industry.
Big Tech does not buy these data centers and operate them itself; instead the data centers are built by construction companies and then purchased by data center operators who lease them to (say) OpenAI, Meta or Amazon (see here). Wall Street private equity firms such as Blackstone and KKR are investing billions of dollars to buy up these data center operators, using commercial mortgage-backed securities as source funding. Data center real estate is a new, hyped-up asset class that is beginning to dominate financial portfolios. Blackstone calls data centers one of its “highest conviction investments.” Wall Street loves the lease-contracts of data centers which offer long-term stable, predictable income, paid by AAA-rated clients like AWS, Microsoft and Google. Some Cassandras are warning of a potential oversupply of data centers, but given that “the future will be based on GenAI”, what could possibly go wrong?
FIGURE 3
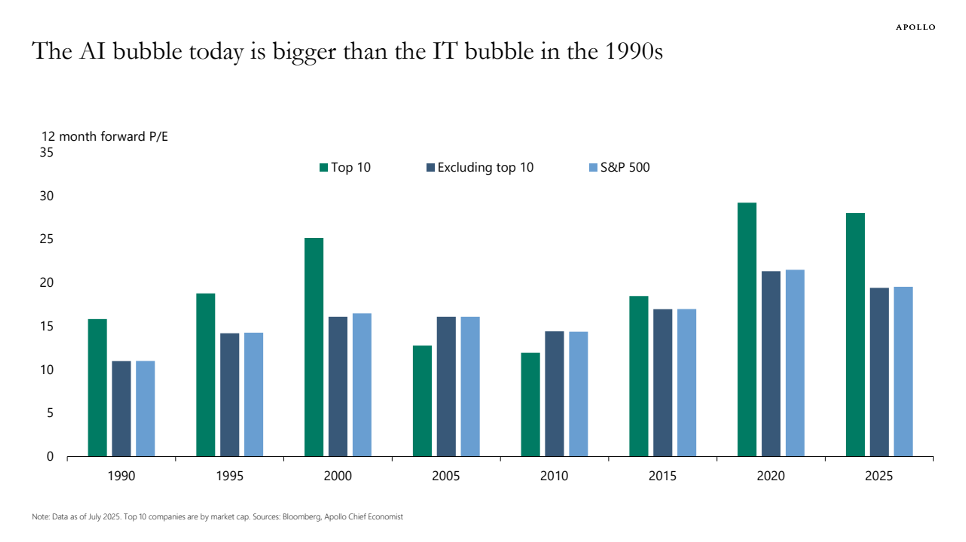
Source: Torsten Sløk (2025), https://www.apolloacademy.com/…
In a rare moment of frankness, OpenAI CEO Sam Altman had it right. “Are we in a phase where investors as a whole are overexcited about AI?” Altman said during a dinner interview with reporters in San Francisco in August. “My opinion is yes.” He also compared today’s AI investment frenzy to the dot-com bubble of the late 1990s. “Someone’s gonna get burned there, I think,” Altman said. “Someone is going to lose a phenomenal amount of money – we don’t know who …”, but (going by what happened in earlier bubbles) it will most likely not be Altman himself.
The question therefore is: How long investors will continue to prop up sky-high valuations of the key firms in the GenAI race remains to be seen. Earnings of the AI industry continue to pale in comparison to the tens of billions of U.S. dollars that are spent on data center growth. According to an upbeat S&P Global research note published in June, 2025 the GenAI market is projected to generate $85 billion in revenue 2029. However, Alphabet, Google, Amazon and Meta together will spend nearly $400 billion on capital expenditures in 2025 alone. At the same time, the AI industry has a combined revenue that is little more than the revenue of the smart-watch industry (Zitron 2025).
So, what if GenAI just is not profitable? This question is pertinent in view of the rapidly diminishing returns to the stratospheric capital expenditures on GenAI and data centers and the disappointing user-experience of 95% of firms that adopted AI. One of the largest hedge funds in the world, Florida-based Elliott, told clients that AI is overhyped and Nvidia is in a bubble, adding that many AI products are “never going to be cost-efficient, never going to actually work right, will take up too much energy, or will prove to be untrustworthy.” “There are few real uses,” it said, other than “summarizing notes of meetings, generating reports and helping with computer coding”. It added that it was “skeptical” that Big Tech companies would keep buying the chipmaker’s graphics processing units in such high volumes.
Locking billions of U.S. dollars in into AI-focused data centers without a clear exit strategy for these investments in case the AI craze ends, only means that systemic risk in finance and the economy is building. With data-center investments driving U.S. economic growth, the American economy has become dependent on a handful of corporations, which have not yet managed to generate one dollar of profit on the ‘compute’ done by these data center investments.
America’s High-Stakes Geopolitical Get Gone Wrong
The AI boom (bubble) developed with the support of both major political parties in the U.S. The vision of American firms pushing the AI frontier and reaching GenAI first is widely shared — in fact, there is a bipartisan consensus on how important it is that the U.S. should win the global AI race. America’s industrial capability is critically dependent on a number of potential adversary nation-states, including China. In this context, America’s lead in GenAI is considered to constitute a potential very powerful geopolitical lever: If America manages to get to AGI first, so the analysis goes, it can build up an overwhelming long-term advantage over especially China (see Farrell).
That is the reason why Silicon Valley, Wall Street and the Trump administration are doubling down on the “AGI First” strategy. But astute observers highlight the costs and risks of this strategy. Prominently, Eric Schmidt and Selina Xuworry, in the New York Times of August 19, 2025, that “Silicon Valley has grown so enamored with accomplishing this goal [of AGI] that it’s alienating the general public and, worse, bypassing crucial opportunities to use the technology that already exists. In being solely fixated on this objective, our nation risks falling behind China, which is far less concerned with creating A.I. powerful enough to surpass humans and much more focused on using the technology we have now.”
Schmidt and Xu are rightly worried. Perhaps the plight of the U.S. economy is captured best by OpenAI’s Sam Altman who fantasizes about putting his data centers in space: “Like, maybe we build a big Dyson sphere around the solar system and say, “Hey, it actually makes no sense to put these on Earth.”” For as long as such ‘hallucinations’ on using solar-collecting satellites to harvest (unlimited) star power continue to convince gullible financial investors, the government and users of the “magic” of AI and the AI industry, the U.S. economy is surely doomed.


OpenAI’s Altman boasted that AGI can “discover new science,” because “I think we’ve cracked reasoning in the models,”
Clearly Altman doesn’t know how science is done. I have, for instance, done an AI search on a theme I used to be an expert years ago namely the cell-to-cell-movement of viruses in plants. With google AI what you obtain is a rehash of ideas more or less currently known. Very importantly, it comes without caveats, critical thinking and without any real experimental data already obtained with its experimental context. The first thing a researcher has to do is to be very critical on any data obtained before, conscientious that all that data was obtained in certain experimental conditions which very frequently result in situations in which the functioning of things are altered or controlled. In this sense, many research results are artificial artefacts and the results of research are often misleading and needing more checks and controls. I very well remember a congress (in Capetown 2001) about plasmodesmata , structures that bridge and communicate plant cells. Virus cell-to-cell movement was amongst the main issues in this small, very specialized, meeting. In a session dedicated to this issue there was a researcher exposing a vast body of research the lab had been doing using state-of-the-art methodology. This included data already published (several articles) and in the same line of research new data to be published soon with important conclusions. In the same session, a different research group using different state-of-the-art methodologies obtained results which suggested conclusions quite different to those that the first group had reached. There was a very interesting and heated discussion on the matter. It was obvious that one of the researchers had immersed in a rabbit hole of experimental artefacts. You can call it hallucinatory results. So humans can indeed hallucinate sometimes and this is apparently what AI machines are learning top do: hallucinate. Starting any research with the very redacted rehash of ideas without any kind of critical thinking looks to me the exact recipe for hallucinatory AI-driven research.
You’ve touched upon what AI boosters are hoping for (AGI) and what the limitations of the current state of affairs are and why humans will be sticking around, especially in knowledge generation fields, for some time still.
I remember there being some links here on Naked Capitalism that touched on symbolic computation, and how that got discarded for machine learning/statistical approaches in AI, which were highly successful in tackling computer vision/classification problems, and led to a winter in research in symbolic methods, which researchers are slowly rediscovering will be essential for AGI.
In this case, symbolic computation would be invaluable for any type of “thinking machine” to simplify contradictory information into abstract logical terms, recognize they form a contradictory set of statements, and then work around that to identify what could be the cause of contradiction, and how it could be resolved, while recognizing a limitation in its own knowledge set to be able to resolve it.
Much of scientific research is dedicated to finding and resolving these contradictions. Phenomenon A predicts X happens in some novel set of circumstances. Phenomenon B predicts Y happens in the same novel set of circumstances. Except in pure mathematics, you can’t ‘reason’ your way through whether A and/or B will fail when tested in those novel circumstances. Likewise as you described, testing a phenomenon A in circumstances X and in presumably the same circumstances X’ generated different results. Reasoning can help identify what may caused different results in this instance, but current LLMs aren’t performing this type of reasoning.
Anyone who’s knowledgeable in physics would understand these limitations. We’ve dedicated billions of hours of research into trying to reconcile quantum physics with general relativity, an instance of where two theories cannot be reconciled where both gravitational and quantum effects are significant. Much of that research gave us string theory, but string theory itself suffers from a lack of testable and verifiable circumstances, and also has gaps in certain circumstances.
As for the life sciences, I’ve seen AI boosters try to remark that LLMs are extremely advanced, since now they’ve begun creating “designer viruses” or “designer gene therapies” that are engineered to achieve certain therapeutic or other effects. However, I’ve been frustrated to try and explain that first, it didn’t actually engineer it, it only proposed it, or “hallucinated it” as you said. Until it actually gets tested or synthesized in a lab, there might be some underlying principle it ignored in its proposal that will prevent synthesizing it. Second, we’ve never actually needed LLMs to do this. Maybe COVID induced brain fog in a lot of people, but October 1st this year marked the 25th anniversary of Folding At Home. Distributed protein folding setups were quite popular, where you could have your computer or game console experiment with trying to find potential new organic compounds by simulating protein dynamics.
I’ve bolded potential and simulating there, because finding candidates or isolating certain functionality was only half the battle, experiments were still needed to validate the results or exploit the actual predicted behavior of how those proteins interacted. LLMs suggesting novel genetics are using similar statistical mechanisms to do this, albeit in a less specialized, and thus less accurate and energy efficient way.
I have a conspiratorial notion that those pushing forward these massive capital spending sprees know these limitations, and maybe their intention is to turn all of these data centers into biomedical research simulation labs when everyone else catches on that simulating clerical work isn’t that profitable. All of these GPUs and hardware setups are well suited to be adapted into giant protein dynamic simulation clusters. However protein folding doesn’t sound as sexy to Silicon valley investors as replacing human workers.
Thank you for your interesting reply Chris. Indeed, computing models are very useful for, for instance, simulating protein dynamics, their folding and changes these undergo under different conditions. There is no human brain that can store all the information available and needed for such simulations. The simulations themselves are to be taken with (tons of) grains of salt. Scientists know that these are just simulations. I think that a big effort has been dedicated to obtain improved versions of RUBISCO, the protein that fixes CO2 to be incorporated in organic material and thought to be the most abundant protein in the world (here an example on Machine Learning to accelerate the process). This kind of work is termed in silico analysis. It isn’t obviously experimental. Whether ML will indeed accelerate the process or make it more complicated it is something that has not been readily shown in this case. It might be that other methods based on random procedures are more efficient and faster.
Chris N: I have a conspiratorial notion that those pushing forward these massive capital spending sprees know these limitations, and maybe their intention is to turn all of these data centers into biomedical research simulation labs
Of course. That’s exactly what’s happening and biomedical research simulations are one intention. Among others.
It’s naive to announce the bleeding obvious, that LLMs can’t hyperscale to more AI or to AGI — whatever that is — as the OP above and many commentators here do as if this were a revelation. Or to point out that LLM-based AI is a bubble. Of course, it is — that’s arguably the business model. The executives running the companies building these giant datacenters almost all went through the dotcom bubble, after all.
Ask the next question. (You’re the only person here I’ve seen starting to do that, Chris.) What are they going to do with all that compute besides LLMs?
How much compute are we talking about? Currently, the world’s fastest supercomputer is El Capitan, at Lawrence Livermore National Laboratory, capable of 2.746 exaFLOPS —
https://en.m.wikipedia.org/wiki/El_Capitan_(supercomputer).
Microsoft is building Fairwater, an AI-focused datecenter in Wisconsin, operational in 2026 that will by comparison supposedly do 17 exaFLOPS and, via massive GPU parallelism, achieve 10x El Capitan’s performance. And this is only one datacenter among others Microsoft is building and which we can presume therefore will get built. (As opposed to speculating, forex, about how much of the Oracle-Softbank-OpenAIStargate effort will come to fruition).
So what other kinds of AI architectures can run in such datacenters. Over the next 3 years, here’s some of the roadmap —
Large Physics Models (LPMs): Foundation models trained on physics texts, equations, and experimental data, capable of reasoning across scales—from QM to cosmology.
Graph Neural Networks (GNNs): For modeling relational systems like molecules, social networks, or traffic flows, where entities and their interactions evolve dynamically.
Neural PDE Solvers: AI systems that learn to approximate solutions to partial differential equations (PDEs), for simulations in fluid dynamics, climate modeling, and fusion energy.
Agent-Based Simulation Models (ABMs): These simulate individual decision-makers (humans, cells, vehicles) whose behaviors evolve based on learned rules, for applications in economics, epidemiology, and urban planning.
In 3-7 years’ time, the hope/intent is to leverage this massive datacenter compute to develop neuromorphic computing, which will need massively lower energy inputs (i.e. like the human brain). That way, AI can be pushed out the Edge, as it’s now being referred to, with the Edge meaning autonomous cars, robots, etc.
Now, how much of this will happen? Well, prediction is hard, especially about the future. But one other factor needs consideration here: we’ve entered a period of geopolitical conflict, unrest, and war, and war generally accelerates technological development — e.g.the state of things pre-WW2 with biplanes and radio to post-WW2, five years later, with jets, rockets, television, and computers.
And this is without the climate threat. So, this could a period of greater technological acceleration than we’ve seen in our lifetimes previously.
Who’s they? This GPU compute needs to earn some kind of yield that compensates for the risk undertaken by the investors. And it’s only suitable for a handful of very specialized workloads. Who’s going to pay for this cool-sounding science stuff? Capitalists certainly are not altruistic.
They can’t do anything like Uber-for-pets with it.
Capitalists aren’t altruistic, but they are greedy, and are willing to invest large amounts of money into things if they think they’ll get a return from them, not because they necessarily or actually will get a return from them.
In this case T Rowe price, Vanguard, and every other 401k or pension fund manager is basically putting money into this because of the predicted productivity ramifications from it. I.E. worker output is going to double translates to double value generated, translates to double revenue generated, translates to earnings increasing many times over.
However, if that doesn’t materialize, and the bubble pops, there will be all of this hardware left over. Even if the hardware is old, it won’t actually be obsolete. I mentioned folding at home, because many of these types of simulations are embarrassingly parallel computational problems, or those where any computer of any power level can contribute towards calculations. Those GPUs will still be useful for anything that requires a lot of matrix multiplication.
This means there will be discount sales for a lot of these data centers, providing opportunities for others companies or investors to buy them up for less than what it would have cost to construct them and buy the hardware new. This is the conspiracy that I’m alluding to: Entrepreneurs can’t pitch a use-biochemical-simulations-to-solve-aging start-up because the time horizon is too long, and initial captial cost too risky to convince non-technical investors to pitch in. But if they can convince them to put money into something that they see a return on, and use that to lower the initial capital cost for their own pet project, they’ll go ahead and do that and fund the entire endeavor for either themselves or their associates interested in those ideas after the crash.
As a tangentially related thought, Elizabeth Holmes’ former partner is starting up another medical testing and diagnostics company. A lot of people from the Rational/Less-Wrong Sphere, who came up with Effective Altruism and Long-termism, have a deep cult-like interest in trying to overcome death, either by uploading consciousness into machines, or through mastering genetics and developing therapies to reverse aging. If these individuals lacked scruples to defraud investors via cryptocurrency (See Sam Bankman-Fried and FTX), I wouldn’t be surprised if they’re willing to defraud investors because in their moral calculus, raising lifespans to be 10x longer than they are now is worth it, even if some proportion of the population dies from impoverishment from the bubble crashing, because the net result was positive for the survivors.
Interesting you mention this, a story in NY Times earlier this week some researchers at OpenAI left to do a startup that takes these kinds of inputs and then claims they’ll have robotic researchers that will actually perform the experimentation itself physically in a lab, presumably a brute force kind of approach to testing.
I can only imagine the number of combinations that might need to be tested for any hypothesis.
I believe a similar folding project, AlphaFold, was able to achieve using generative AI/DeepMind what Folding At Home was setting to accomplish; they were awarded the 2024 Nobel Prize in Chemistry for their achievement.
PapP: I believe a similar folding project, AlphaFold, was able to achieve using generative AI/DeepMind what Folding At Home was setting to accomplish
Essentially, with some differences.
AlphaFold used a transformer architecture to model relationships between amino acids similiarly to how LLMs model word dependencies and has attention mechanisms that work across both sequence and spatial dimensions, similarly to how LLMs track long-range dependencies in text.
Differences were no autoregressive token prediction — AlphaFold doesn’t generate sequences, it infers structures — and optimization for protein folding, not open-ended tasks.
LLM architectures are pattern-seeking recognition architectures, after all. As Ignacio says above: “There is no human brain that can store all the information available and needed” to work out some biogenetic relationships. Turn an optimized LLM loose on non-semantic data sets and you sometimes get amazing results.
~~
Conversely, giving a free version of ChatGPT semantics-based tasks simply to prove LLMs aren’t really intelligent in order to validate your prior anti-LLM beliefs, as many in the NC commentariat are doing, accomplishes — what?
Certainly, it’ll give you the proof that the free LLM system for the masses that you used isn’t intelligent, but just a dumb stochastic pattern-recognition system. But it tells you nothing about what specialized LLMs can achieve at full stretch. So, if you believe it does, who’s the joke on? Because it’s not on the LLM, which is indeed just a dumb stochastic pattern-recognition system.
This got me thinking about Kurt Gödel and his Numbering System as applied to LLM architecture with regards to patterns/tokens; these are axiomatic systems govern by simple rules woven together into a regression. So if this is the case, then this is an at least formal-like system and will be ultimately be Incomplete even if you account for the largest vocabulary/library of everything ever written (the totality of the Library of Babel from Jorge Borges comes to mind).
So is this chase for AGI a fool’s errand if we can’t even prove AGI on a formal level?
What does this say about us on a formal level?
Maybe we can relate to this other ontological thing as a fellow confused pattern-recognizing being?
Not equal but different.
Regarding the replacement of journalists i believe that there are some of a kind who can be easily replaced by AI. Those whose work consists on following a script and who are so frequently and sadly found in MSM. AI can probably do it more reliably. In fact they probably use AI tools to write their articles.
I think it’s worth pointing out here that these GPUs go obsolete in 6-12 months, so their value drops sharply. Their collateral is like fresh fish. They have to hold on to it, but it will inevitably make a huge stink.
Obsolete does not mean useless. Machines that are not state of the art still work and can perform functions that do not require the latest and greatest hardware. However, in a hyper competitive environment, everyone naturally wants to be at the cutting edge.
Obsolete means useless as debt collateral, since the asset loses much of its value.
It seems that with computer operating systems software (OS), the free & open source (FOSS) Linux has proven to be superior to non-FOSS/closed OS software like Windows.
What are the prospects for FOSS in AI/LLM? Is there a similar likelihood that a FOSS software in AI/LLM like DeepSeek will outperform the US closed competitors like OpenAI? If no AI/LLM software is producing the hyped extreme productivity breakthroughs, wouldn’t there be an incentive globally in most nations to use or make limited propietary modifications on DeepSeek instead of the US closed software alternatives. Especially if it is the case that DeepSeek can provide similar quality models with 10% of Meta’s AI software’s computing power.
Any computer scientists or financial analysts/economists focused on the InfoTech sector have a take on how a FOSS software like DeepSeek will influence future AI development?
“What are the prospects for FOSS in AI/LLM? Is there a similar likelihood that a FOSS software in AI/LLM like DeepSeek will outperform the US closed competitors like OpenAI?”
Sure thing bro, just search for “running deep seek on raspberry pi and you’ll get a long list of how to do it and many examples of it running.
Raspberry is a very cheap one board computer that runs linux.
https://www.hackster.io/ElecrowOfficial/how-to-run-deepseek-on-a-raspberry-pi-5-step-by-step-guide-c2c790
There’s a big difference between what FOSS can do and what it does do. Mostly the difference between what a motivated individual wants and what a pointy haired boss wants. ProNewerDeal claims Linux is superior (I agree, personally), but that hasn’t budged the needle on desktop market share, has it?
Sure, you can shoehorn a LLM onto a Pi (it’ll run like molasses in January), but what CEO is going to boast about that to a quarterly analyst conference call? The CapEx orgy is hype driven, not performance driven (duh). This is an apples / oranges question.
The real worry is that the current AI ‘productivity’ hype was a head fake to fund the infrastructure, and the real goal is to get everyone hooked on AI (a la Facebook/TicTok), dumb down the population, grab Google’s advertising money firehose and end up owning the mother of all Big Brother propaganda engines.
I recently stumbled into some on-line drama about how the latest OpenAI model was messing with paying customer’s feels, by routing “dangerous or emotional” prompts to a safer model which was heavy on the warnings, and offering up information about self harm hotlines and such, rather than playing along like the previous model. Oh the humanity!
I gather that paying customers can select the older model, but there’s real-time “psychological analysis” of your prompts so if it judges that you’re veering into dangerous territory, it routes to a newer, safer model. And let me tell you, THEY DONT LIKE IT!
From my 30 minute climb down that rabbit hole, I came to the conclusion that there’s already a lot of people well on their way to the LLM addiction you mentioned in your last paragraph.
It may not be plain jane FOSS, but Linux derivatives are being used by the biggest of big boys:
Inside Google‘s Data Centers: The Operating Systems Powering Google‘s Global Infrastructure
https://expertbeacon.com/inside-googles-data-centers-the-operating-systems-powering-googles-global-infrastructure/
The article also mentions that Linux derivatives are used by Amazon and Facebook.
Admittedly, using a Pi for an LLM is probably not going to work too well, but AMD’s latest high end laptop CPUs are bringing some real heat if you want to do LLM at home:
Linux on the New Framework Desktop PC! https://www.youtube.com/watch?v=ziZDzrDI7AM
That’s definitely NOT a cheap PC, but the LLM performance is pretty astonishing even at that price point.
Overall though, I agree that AI is way, way over hyped for what it’s actually doing. But strangely, AI in other countries (at least one other country) is actually doing some pretty amazing stuff:
China’s AI hospitals will transform medicine across the world. But not in the United States. https://www.youtube.com/watch?v=XDmFB7AQSR0
China is already a powerhouse in AI for radiology and medical imaging. Next they’re going global. https://www.youtube.com/watch?v=3RJlqhYt2XQ
AI in America strikes me as a “cheat”. American elites don’t have to do the real hard work to compete with a country like China (like re-industrialize, bring back R&D, re-create a skilled middle class workforce) , AI will just figure it all out and “poof”, America is on top again! It’s a nice dream for our elites, but it’s a dream that can turn into a nightmare for the rest of us.
Glen: AI in America strikes me as a “cheat”. American elites don’t have to do the real hard work to compete with a country like China (like re-industrialize, bring back R&D, re-create a skilled middle class workforce) , AI will just figure it all out and “poof”, America is on top again! It’s a nice dream for our elites .. that can turn into a nightmare for the rest of us.
Yes.
The trend is broadly recapitulating nuclear, which American capitalism — where corporate elites had to be served and profit before all else — also screwed up. Also, automobiles. Also, airliners (e.g. current Boeing failures).
Don’t quote Silicon Valley at me, because that was built on Pentagon money; in 1960, 100 percent of all microprocessor chips it produced were bought by the DoD for ICBM guidance systems and early-warning radar networks like NORAD; as late as 1967, 75 percent of all chips from Silicon Valley were still going to the DoD.
It took the Japanese to pioneer transistor/chip based electronic consumer appliances — computer tech for the civilian masses — not the Americans.
Thanks for this excellent article. Indeed, the whole idea that LLMs are going to lead to AGI is just a laughable fantasy. Perhaps if Sam Altman hadn’t dropped out of a comp sci program, he might know this, but he’s from a rich family so he could always retreat back into money and vast carelessness.
And then we get to the whole issue of data centers, their costs, the investment bubble, etc.
Regarding the question about FOSS alternatives, and alternatives to the big data center apps…
One of my colleagues has been experimenting with local LLMs. This colleague is a professional software engineer with decades of experience.
Key findings about local LLMs:
* Vision detection using an Intel Arc A770 (12GB of ram) works but gives many false positives.
* Voice commands work only for the simplest commands. Anything beyond “turn on the kitchen light” fails to translate into expected actions.
* Trying to write kubernetes YAML — the results are so terrible it’s just laughable.
* Code generated in other languages “utter trash”.
* Trying to resolve actual networking problems gives the same few suggestions, all of which were incorrect.
* Trying to solve networking problems with cloud-based LLMs isn’t much better.
* Using the app for an interactive diary, it got stuck in discussion loops after a few days.
* Open source LLMs on Hugging Face are always well behind the commercial offerings from OpenAI et alia.
Conclusion: currently-available local LLMs are simply not usable for many problems, or will cost too much to produce better results.
From my vantage point, a lot of the hype around generative AI is being sustained by people who stumble through vibe coding a basic app and then say “wow, this is amazing — I wrote an app but I didn’t have to learn to code!” Basically, these are people looking for a free lunch. They want to be able to say “I wrote an app” but they don’t want to make the effort to learn a programming language.
There are also those who say they want to learn, but in fact they are unwilling to just sit down and read a book. There are hundreds and hundreds of books about many different programming languages, expressly for this purpose. E.g., once upon a time, I read Kernighan and Ritchie’s The C Programming Language. It’s well-written and not very long. This is the tried and true way of doing it.
But vibe coders don’t want to make such an effort. They want to “chat” with an AI to “learn” what they would get from simply reading a book. In other words, they want hold-holding and fawning attention from a sycophantic bot, all the way through.
The unspoken premise here is that learning a programming language is some sort of insanely difficult task — but is it really? IMO, this leads us directly to a deeper issue, which is people who expect rewards — or actually feel entitled to those rewards — but don’t want to make any effort to get those rewards.
What i found more damning is that while there are indeed applications for which de LLM models can be useful and help humans with some cumbersome tasks the big 7 keep focused on AGI. Interesting but boring business models bypassed in the search for some utopian or dystopian tech control of everything. The bubble is very, very high above us. And agreed: very good article.
“…once upon a time, I read…”
This is actually the key failing of AI. You read and comprehended something. LLM’s are given information to make statistically inferred outputs. They don’t read nor comprehend the information that was provided to them in training.
I have some limited experience with local LLMs. It was like working with a 3 year old… but unlike a 3 year old, it never learned and kept making the same mistakes. Once in a while, I got better results without changing anything, and other times worse.
Software engineer here. I can’t add much to this, unless the idea of AI code generation is to change my job from thinking about solutions to business concerns to thinking about editing the AI’s probabilistic solutions to business concerns, is the order of the day.
Of course the there has been some big talk, but not many takers yet it seems. Amazon made hay over exactly this not long ago, as if the efficiency gains are something you can now take to the bank, and removed “tens of thousands” of workers from their rolls. But a few months later it turns out they just wanted to hire a bunch of H1b visa holders instead. Turns out AI ‘efficiency gains’ are simply wage cuts:
https://arstechnica.com/tech-policy/2025/09/amazon-blamed-ai-for-layoffs-then-hired-cheap-h1-b-workers-senators-allege/
“Those aren’t eatin’ sardines, their tradin’ sardines.”
*they’re
too early in the morning to try to be witty.
sardine (n.) : “pilchard, type of small oily fish,” migratory and highly esteemed as a food, early 15c., from Latin sardina, sarda, from late Greek sardinē, sardinos, earlier sardē, which is often said to be from or related to Sardō “Sardinia” (see Sardinia), the Mediterranean island, near which the fish probably were caught and from which they were exported.
which takes us back to the previous discussion of Sardonic Laughter.
When i was in Cali i didn’t ask for pilchards but sardines and it was better understood by many sellers there. You know what happens with fish names: they are local and you have plenty of regional variations which apply to some similar fish species. If you enter “sardine” in fishbase you obtain 63 entries from many different regions representing more than two dozen species besides Sardina pilchardus.
My wife has had a curious experience with AI-driven decisions taken in a Spanish bank. She was being charged some commissions on her account which according to bank rules were not applicable in this account. She went to a branch to get those removed and dis-charged. The person attending her agreed that she was right but when she tried, the AI algorithms didn’t allow to remove the commission because some obscure “original sin”, let’s call it this way, coming from the merger of the original bank where the account had been opened long ago. In the end this has been solved by a helping attendant who decided that the only way to do this was to deceive the algorithm with false data. You can imagine where is this all going when you have to resort to tricks.
Sounds like a great way to have a crooked bank employee feed the AI algorithm some dodgy data so that bank funds are sent to an account that may not be “officially” listed. Would banks miss money going into a bank account that they cannot find listed in their files or even know about?
That sounds a lot like the begging process that medical professionals face, with insurance company “care approval” protocols. There is no shortage of stories about doctors and patients trying to get timely care coverage. Insurers claim cost savings and better care, but charts suggest otherwise.
There is a thingy about this on the Netflix show Barry and is in real life the Australian Robo Debt debacle – https://www.abc.net.au/news/2025-09-04/robodebt-victims-get-compensation-from-class-action/105734030
I mean its not like there is some decades of these machinations in the “Market Place” and some are still confused … HR is old hat now lmmao …
This is a tangent, but bear with me – it’s good and kinda relevant. The last link in the article is to a Science News Today article about building a “Dyson Sphere.” The article states:
This is fake news (and a very common misconception). Freeman Dyson was making fun of the tortured logic used by SETI scientists to explain why they thought looking for particular radio waves would be a reasonable way to scan the stars for life. The article in which Dyson proposed the sphere was a one-page parody letter to an astro-physics journal. Unfortunately, a lot of people don’t get dry humor (which is extremely obvious when you read the actual ‘paper’) and took him seriously. Dyson himself thought it was funny that he was best known for a joke he made instead of any of the actual physics he did.
At any rate, the fact that a science news website is acting like Dyson Spheres make any sense at all (they don’t, and purposely so) is pretty indicative of where we’re at as a society…i.e. pretty far down the path to Idiocracy. So the guy bringing us GenAI talking about building Dyson Spheres is pretty on-brand. The best part of Altman’s quote got cut out in the article, however. Right after mentioning Dyson spheres, he says, “Like probably in the next 10 years or something.” roflmao.
IBM TV ad on streaming: “Blue gonna help you transform your business with AI.”
Reminds me of the TQM craze, everyone chased it no one read Deming!
It’s doing wonders for their stock price, though. Victory!
Why does this whole sorry episode remind me of the Biblical story of The Tower of Babel?
It will all end in tears …
As of last night, it finally dawned on me that I’ve been noticing what must be AI generated text in the description feeds to my Amazon Prime video account feeds.
The first one I saw, but didn’t recognize it at the time as an AI hallucination, was a movie with the description that started something like, “Set in the 1920’s…”. However watching the trailer it was obvious the story was more modern, but the one item that probably threw me was there was one brief photo in the trailer that was older – maybe from the 1920’s.
Anyhow I was confused enough by it that I just kept skipping it. Then last night I watch “The Healer”. It’s intro text started something like, “From the 17th century…” but again the trailer was all modern. I mentally just assumed the 17th century was a reference to a family history of healers which was part of the story line (that it was a family thing). However, after watching it there is NEVER any mention of anything from the 17th century. Then it dawned on me that it might be an AI hallucination. When I even went to the Amazon website the descriptive text there for “The Healer” never said anything about the 17th century, it was only in my Amazon Prime feed from the app on my Android TV.
I am now certain my confusion over the “Set in the 1920’s” is also a hallucination.
For all your readers who are interested in the history of AI’s coming into being in its current form Matteo Pasquinelli’s book, ‘The Eye of the Master: a social history of Artificial Intelligence’ is indepensable. It chartes the battles of the neuroscience sector, the interests of the US navy and Marxist analysis of labour power with formidable argument to demonstrate the deep flaws in AI’s claims to triumphant revolution.
Well, with AI replacing labor, AI robotics replacing labor, AI replacing thinking … AI replacing…..
with AI getting all the money to be productive while actual humans have income while that income is depleted more and more by out-go. You would think that fewer and fewer people will be able to afford the purchase or consumption of these magical AI fantasies.
I guess if humans are to be digitized to the point of no choice, well then, AI will have all the biological imput devices for it’s consumption and outputs designed to maximize profits
I am waiting for AI to come of age in law and take over for lawyers and judges. Between the constant stories of AI hallucinations re: legal case, and anecdotes about AIs learning to “cheat,” I can only imagine what sort of dystopic Wild West is coming for the court system…
“The disappointing rollout of ChatGPT-5 raises doubts about OpenAI’s ability to build and market consumer products that users are willing to pay for. But the point I want to make is not just about OpenAI: the American AI industry as a whole has been built on the premise that AGI is just around the corner. All that is needed is sufficient “compute”, i.e., millions of Nvidia AI GPUs, enough data centers and sufficient cheap electricity to do the massive statistical pattern mapping needed to generate (a semblance of) “intelligence”. This, in turn, means that “scaling” (investing billions of U.S. dollars in chips and data centers) is the one-and-only way forward — and this is exactly what the tech firms, Silicon Valley venture capitalists and Wall Street financiers are good at: mobilizing and spending funds, this time for “scaling-up” generative AI and building data centers to support all the expected future demand for AI use.”
The disappointing performance of the COVID-19 vaccines raises doubts about Biomedicine’s ability to read and understand the scientific literature, which has demonstrated conclusively that durable immunity to coronaviruses is unattainable in vertebrates, either through previous infection or vaccination. Nevertheless, Operation Warp Speed was built on the premise that after everyone was vaccinated the pandemic would recede into nothingness. Cost was no object, and a few transnational Big Pharma corporations made tens of billions of dollars during 2021 and 2022, with the expectation of a continuing money stream after the initial surge in vaccinations. This approach was the only way forward and would lead to a revolution in rapid responses to future emerging infectious diseases using mRNA vaccines. And the scientists who figured out how to stabilize expression of exogenous mRNA in the target cells and tissues were awarded a Nobel Prize for their previously underappreciated research.
Some calm reflection is in order. If all progress in AI development stopped cold today, it would take 20 years for its benefits to percolate through the world economy. Note that the productivity potential of networked computer technology and uniform electronic data standards available 20 years ago has still not been achieved, largely because of institutional behavioral inertia. The gating factor in the application of intelligence to the problems of man is not the pace of the synthesis of intelligence, it is the unwillingness of mankind to behave intelligently in accepting change.
We know how to make universal medical charts and records. We know how to fully automate air traffic control. We know how to prevent train collisions. We know how to build trusted voting systems. But we are good at finding reasons for not doing the things we say we want to accomplish. Of course, when something becomes an “emergency,” suddenly the obvious is discovered. Welcome to the modern world: powered by emergencies, not emergent technologies.
It ought to be remembered that there is nothing more difficult to take in hand, more perilous to conduct, or more uncertain in its success, than to take the lead in the introduction of a new order of things.
— Niccolò Machiavelli
This IS calm reflection, and not a moment too soon, in the face of too much cult-like marketing hype.
Who is this “we” that will harness technology for the good of mankind? If recent history has shown us anything at all, it is that the application of new technologies—at least in the Western world—will be controlled by the most ruthlessly exploitive financial interests and used primarily if not exclusively to extract value from everyone else. This is the opposite of broadbased dissemination and learning that filters into quality improvements across sectors, raising living standards.
My sister is a nurse. I’ve heard quite a bit about the rollout and aftermath of the EPIC medical management system. It is not designed to help medical providers or improve patient care. It’s about billing, full stop, and it’s hated by pretty much everyone she knows in her field.
“We know how to make universal medical charts and records.”
Yes, we do. And they have very little to do with improving healthcare and everything to do with billing and upcoding. No single $8-ibuprofen tablet shall remain unaccounted for! It is also true that AI transcribed charts are often replete with mistranslations and outright hallucinations.
It is a sad fact that U.S. hospitals have effectively resisted the automation and interoperability of their systems for decades. Medical professionals have insisted on preserving institutional moats and drawbridges that render their computer systems highly incompatible, despite the obvious need to track the same patient information. There is no digital standard for the patient chart, the most basic medical record. Between 5 to 10 percent of patients are harmed by medical error. Surely uniform AI cross checks on diagnosis and treatment would reduce that. Put on top of this a health insurance structure that only M.C. Escher could depict, and you have an inefficient mess attributable not to evil computer geniuses, but to institutional turf wars, perverse incentives, and just plain cussedness.
It’s not just medical institutions. Look at the power grid, the rail system, pipeline infrastructure, and air traffic control. Look at the inability to build housing, the plague of homeless mentally ill people, all in a nation that is among the richest in the world. Is misguided technology speculation really a central problem?
Is misguided technology speculation [that will probably crash a debt-ridden economy] really a central problem?
It sounds bad to me…
Private Debt mate
“Is misguided technology speculation really a central problem?”
It’s certainly not the solution.
Most of this is due to the category error that his health insurance. People insure their lives and property against events that are unlikely. Illness and accident are not in this category. No argument from me that if healthcare were the objective instead of private profit (even in “nonprofit” hospitals), interoperability and legitimate electronic health records could be useful and universal and improve healthcare all around.
According to STAT yesterday, UpToDate is unveiling its AI version. UpToDate has become the near universal cheat sheet for clinicians. Still, from the article:
That kind of explainability is critical as doctors choose when and how to let different AI tools help them, said Crowe. But healthcare AI experts emphasized that those advances have not eliminated the chance for error through hallucinations, omissions, or other more nuanced LLM mistakes.
Stanford’s Chen cited an example in which a resident had treated a patient with severe alcohol withdrawal with phenobarbital, a powerful sedative and anticonvulsant, based on an LLM-based tool’s response. Chen asked the AI the same question, and got the response he expected: First line therapy was safer benzodiazepines, followed by phenobarbital. “AI will just make up some stuff — or even if it doesn’t make up stuff, it’s a little bit random,” he said. “This unpredictability is what allows it to be kind of creative and flexible. But do you want to be creative when you’re practicing medicine?”
Some clinical generative AI tools may perform better than others — depending on their engineering, the data they’re trained on, or their underlying LLMs. There are tradeoffs involved in choosing any subset of medical material to train on. “You are potentially missing some important information if you’re not pulling from more up-to-date resources,” said physician Cornelius James, who researches AI and evidence-based medicine at the University of Michigan. “But you also avoid bias in that you’re not pulling from some of those more up-to-date resources.”
But clinicians are missing the details needed to make informed choices between tools. “The general state of the evidence is terrible,” said neurosurgeon Eric Oermann, who directs the Health AI Research Lab at NYU Langone. Researchers and companies are developing benchmarks that evaluate an LLM’s medical abilities, from simple early versions like taking the U.S. medical licensing exam to those involving real-world patient tasks and clinical reasoning. Benchmarks are imperfect, said Oermann, but at least they allow for researchers to compare large language models from tech companies like Google and OpenAI on a level playing field by peppering their APIs with thousands of programmed questions.
Anyway, I do not think it unreasonable to expect a resident physician to know that benzodiazepines are the preferred choice over phenobarbital for a patient suffering from alcohol withdrawal, which is not a particularly rare condition. It has been said millions times that “being educated means knowing where to look up something.” No, being educated means knowing what you know and what you don’t know.
GingerBalls on the Twitter often points out that there’s an unintelligent solution to every intelligence test, so passing these licensing exams is meaningless.
Participation in the technical aspects of this discussion, which I am reading with great interest, is above my pay grade, but an observation: the medical and pharmaceutical professions, at least in Canada, are currently the sole remaining market for fax machines.
You clearly have not been paying attention to our decade+ posting, based on the work of medical professionals who happen to be experts in IT, as well as the experience of users, that electronic health records are an utter train wreck. And it has NADA to do with your bogus depiction.
The process has been driven by billing and the desire to upcode. Not medical care. Not ever remotely your fabricated “medical professionals preserving institutional moats’.
You need to stop Making Shit Up when you do not know what you are talking about.
Agree with everything here except timing. Some economists tried to quantify the technology diffusion rate and found it’s closer to fifty years instead of twenty if you’re looking at full global adoption.
Smartphones took over the world and changed our brains in less than ten years, on the other hand.
But yes, there are still Homo sap tribes living in the Amazon who don’t know the world outside their forest and are living the way they lived in 20,000 years (though not in the Americas). Personally, I think it’ll be a sad day if and when they cease to be there — because the world is coming for them — though I wouldn’t wish to be one of them.
“Yet AI, which Storm calls “Artificial Information” …
Perfect.
Re: The AI Bubble and the U.S. Economy: How Long Do “Hallucinations” Last? By Servaas Storm
Proper descriptive language is critical to the analysis and reworking of human systems. Therefore, being lulled into repeating truisms that are not true undermines the work being undertaken. In the article, Storm says, “The AI investment boom is based on the belief that AI will make workers and firms significantly more productive, which will in turn boost corporate profits to unprecedented levels.” That phrase is not true. Eliminating “workers and” corrects the statement, ironically, by doing exactly what makes AI so attractive to “firms.”
The idea that automation makes the residual workforce more productive has always been a lie, a lie that has been encouraged by ownership simply because it has some ability to make that residual workforce proud of the machines that make it “the most productive workforce in human history,” even as the latest machines pick off the remaining laborers, one by one. Dividing amount of production by number of laborers to get ever-rising labor productivity figures is a stupid accounting trick. Dividing production by labor equivalent units (LEU’s – and, yes, this is adapted from containerized shipping) gives away the game. By not defining or measuring LEU’s, it veils the possibility that productivity – given that energy and pollution would necessarily be figured into the cost of each LEU – would be revealed as having heretofore invisible periods of stagnation, even regression.
More importantly, defining and measuring LEU’s would eliminate any last trace of simplistically attributing productivity to labor. By dividing measured production between labor and LEU’s, it would make stark the reality that ownership always trumps attribution. Attributed productivity has never given more than a tenuous claim to the profits of production. Labor has always known that. Labor has long been able to project the trend of increasing productivity and has long dreaded that projection: that eventually “labor” would be reduced to a janitor cleaning up after the machines, working for minimum wage, while being attributed trillions in productivity.
Ownership matters. Once nourishment and a safe place to live is secured, ideas are the most valuable commodities, yet “intellectual property” is almost an oxymoron. Technique ends up embedded in tools. That is why, where the guilds were strong, possessing the tools of a craftsman, without being a member of the appropriate guild might actually be a crime. Similarly, the Luddites were not so much opposed to advances in technology as they were the embedding of their intellectual property into an array of machines. Truly, the machinists were the first computer programers, and they feasted on converting the deep skills of others into own-able hardware. Now, the programmers are coming for the artists, the scientists, even the C-suites, and the latest generation of programmers might be the last, as intellectual property devours its producers, and is left to eat its own tail.
But the last programmer will be attributed a vast productivity.
“Eric Schmidt and Selina Xuworry, in the New York Times of August 19, 2025, that “Silicon Valley has grown so enamored with accomplishing this goal [of AGI] that it’s alienating the general public and, worse, bypassing crucial opportunities to use the technology that already exists. In being solely fixated on this objective, our nation risks falling behind China, which is far less concerned with creating A.I. powerful enough to surpass humans and much more focused on using the technology we have now.”
That’s some Chinese characteristics that I endorse.
The USA business and financial sector is preoccupied with trying to insert rent-seeking middle-men between all the issues that could be addressed now – for and by people in the here and now. The people who have to be healthy, sane, and safe in order to have healthy, sane, and safe people in the future.
It’s still just fucking software! What a con!
If you are interested in a detailed outline of the progress of AI in the MIC, here is a great substack that explains what is going on in the field where military combat AI is being developed. It focuses on Arizona and New Mexico because the largest combat military training centers in the world are located there. I foresee a great future for AI as the military has unlimited financing for the large corporations dabbing in that field.
https://sonoransown.substack.com/p/life-recast
I guess this is the terminal phase of the AI bubble, the phase I remember from the dotcom one – if you mention the risks that were mounting by the hour people would yell at you because the objective was to get funding and walk away with all you could in the crash. And in five years somebody buys the infrastructure for pennies on the dollar and turns a profit on porn or whatever.
Only a tiny example of odd experience: I was testing duck.ai as my system is too old to host the new programs.
I wanted duck.ai to shorten a narrative text by 10, then 20, then 50%. For some internal error it cut it down by 90%, 80% and 50% respectively. This failure repeated. It never came up with versions which would be 10% shorter or 20% than what I had fed it with. Strange.
Generally the results with narrative fiction are horrible. What the system is offering (they claim to treat the texts confidential) is either total nonsense or equipped with some sense but solely by coincidence. Containing meaning that has little to do with what I had originally written.
This is especially true – and now any programmer should seriously lsiten up – humour or “poetical” formulations. Style in general is overwhelming it.
Anything where “tonality” comes into play crashes it .
As I said I can´t judge state of the art systems. But unless I tell any AI to reproduce something in the style of say TS Eliot, or Dickens or Austen, it doesn´t know wha to do. It is totally lost and will fail to develope inherent styles of its own. And produce gibberish.
Which shouldn´t surprise.
At the beginning of the industrial revolution, workers rebelled against the machines. They intuited that if they did not own the machines, the machines would own them. This is also the case with robotics in production, “Who owns the robots?”
AI in my thinking is no more than a language and data collecting robot. So, “who owns AI?” We see that financialization and rent-seeking have turned AI research into a mess. By all accounts, researchers in China do not do the same.
#DotComBoomBustMemories
I had a video chat with one of my younger colleagues at work, and they asked me what similarities if any I see between the dot-com-boom, and this new AI-boom. At first, I thought that the dot-com-boom was really more intense flying-by-the-seat-of-ones-pants-into-the-unknown … but as we talked through it, I realized, that this is potentially far worse.
The lemmings from lower Manhattan and the sycophants from the valley of silicon are getting the band back together!
Rare moment of clarity from Eric Schmidt there … he’s already made his billions, though, so I can imagine some of the young guns who are lookin’ to get theirs scoffing at his concern.
Once again, the odious runaway sewage train (via YouTube) of unicorn valuations looks set to derail and spill sh** everywhere. When the colo-business (via dgtlinfra.com) collapsed after the dot-com-bust, a lot of data-center space in NY/NJ, for example, reverted to office space. The intervening years brought public-cloud to the fore, and now public cloud space is set to expand just like metro datacenter space expanded at the turn of the century. One can only imagine the impact of large AI-specific datacenters being built out in the boonies (where land/tax, water and power are cheaper, ostensibly) only to have them decommissioned and empty when the bust invariably comes. Empty strip mall desert redux, anyone?
One of the reasons the tech-bros are focused on “surpassing human intelligence” is because they absolutely loathe labor. The finance bros may seem convinced about AI, but they’re not fully. They want two things:
• Proof that AI can generate new revenue streams – this, they have gotten thus far.
• Proof that AI can kill jobs – this, they haven’t got (to a satisfactory degree yet), and I think this is what they really, really want.
The dumb asses don’t understand how an economy works at all, and are blinded by the dollar signs in their eyes.
So, yeah … bubble, bubble, toil and trouble!
And if, by some chance, this edifice of irrational exuberance somehow manages to survive, just remember: AI is gonna replace everyone … except VC’s … #natch (via futurism.com).
Rare moment of clarity from Eric Schmidt there … he’s already made his billions, though, so I can imagine some of the young guns who are lookin’ to get theirs scoffing at his concern.
I don’t have to imagine. I’ve heard them.
> I don’t have to imagine. I’ve heard them.
Thanks much for the confirmation! I know these types, but don’t share environs often.
Sadly, the article did NOT look at AI in China – but was navel-focused. China AI is primarily focused on the factory, where it actually provides quantifiable cost savings. The US AI has been focused on rendering a larger fraction of the population as inessential workers – to use the language of Bender in Futurama – meatbags – consistent with the disdain the oligarchs have for the lumpen population. Karma when the bubble bursts?
Computers are supposed to compute.
That is their utility
2+2=4,every time
maybe boring, but that is all there is.