Ed Zitron has been relentlessly pursuing the questionable economics of AI and has tentatively identified a bombshell in his latest post, Exclusive: Here’s How Much OpenAI Spends On Inference and Its Revenue Share With Microsoft. If his finding is valid, large language models like ChapGPT are much further from ever becoming economically viable than even optimists imagine. No wonder OpenAI chief Sam Altman has been talking up a bailout.
By way of background, over a series of typically very long and relentlessly documented articles, Zitron has demonstrated (among many other things) the absolutely enormous capital expenditures of the major AI incumbents versus comparatively thin revenues, let alone profits. Zitron’s articles on the enormous cash burn and massive capital misallocation that AI represents have the work of Gary Marcus on fundamental performance shortcomings as de facto companion pieces. A sampling of Marcus’ badly needed sobriety:
5 recent, ominous signs for Generative AI
For a quick verification of how unsustainable OpenAI’s economics are, see the opening paragraph from Marcus’ November 4 article, OpenAI probably can’t make ends meet. That’s where you come in:
A few days ago, Sam Altman got seriously pissed off when Brad Gerstner had the temerity to ask how OpenAI was going to pay the $1.4 trillion in obligations he was taking on, given a mere $13 billion in revenue.
By way of reference, most estimates of the size of the subprime mortgage market centered on $1.3 trillion. And the AAA tranches of the bonds on mortgage pools of AAA bonds were money good in the end, although they did fall in value during the crisis when that was in doubt. And in foreclosures, the homes nearly always had some liquidation value.
Now to Zitron’s latest.
Many, particularly AI advocates in the business press, contend that even if the AI behemoths go bankrupt or are otherwise duds, they will still leave something of considerable value, as the building of the railroads (which spawned many bankruptcies) or the dot-com bubble did.
But those assumptions seem to be often based on a naive view of AI economics, that having made a huge expenditure on training, the ongoing costs of running queries is not high and will drop to bupkis. This was the case with railroads, which had high fixed costs and negligible variable costs. The network effects of Internet businesses produce similar results, with scale increases producing both considerable user benefits and lowering per-customer costs.
That is not the case with AI. Not only are there very large training costs, there are also “inference” costs. And they aren’t just considerable; they have vastly exceeded training cost. The viability of AI depends on inference costs dropping to a comparatively low level.
Zitron’s potentially devastating find is breadcrumbs that suggest that OpenAI’s inference costs are considerably higher than they pretend. Zitron further posits that the user prices for ChatGPT greatly subsidize the inference expenditures. Because the reporting on AI economics by all the big players is so abjectly awful, Zitron’s allegations may well pan out.
First, a detour to explain more about inference. From Primitiva Substacks’ All You Need to Know about Inference Cost from the end of 2024. Emphasis original:
Over the first 16 months after the launch of Gpt-3.5, the market’s attention was fixated on training costs, often making headlines for their staggering scale. However, following the wave of API price cuts in mid-2024, the spotlight has shifted to inference costs—revealing that while training is expensive, inference, even more.
According to Barclays, training the GPT-4 series required approximately $150 million in compute resources. Yet, by the end of 2024, GPT-4’s cumulative inference costs are projected to reach $2.3 billion—15x the cost of training.
As an aside, Gary Marcus pointed out in October that GPT-5 didn’t arrive in 2024 as had been predicted and has been disappointing. Back to Primitiva:
The September 2024 release of GPT-o1 further accelerated compute demand to shift from training towards inference. GPT-o1 generates 50% more tokens per prompt compared to GPT-4o and its enhanced reasoning capabilities result in the generation of inference tokens at 4x output tokens of GPT-4o.
Tokens, the smallest units of textual data processed by models, are central to inference compute. Typically, one word corresponds to about 1.4 tokens. Each token interacts with every parameter in a model, requiring two floating-point operations (FLOPs) per token-parameter pair. Inference compute can be summarized as:
Total FLOPs ≈ Number of Tokens × Model Parameters × 2 FLOPs.
Compounding this volume expansion, the price per token for GPT o1 is 6x that for GPT-4o’s, resulting in a 30-fold increase in total API costs to perform the same task with the new model. Research from Arizona State University shows that, in practical applications, this cost can soar to as much as 70x. Understandably, GPT-o1 has been available only to paid subscribers, with usage capped at 50 prompts per week….
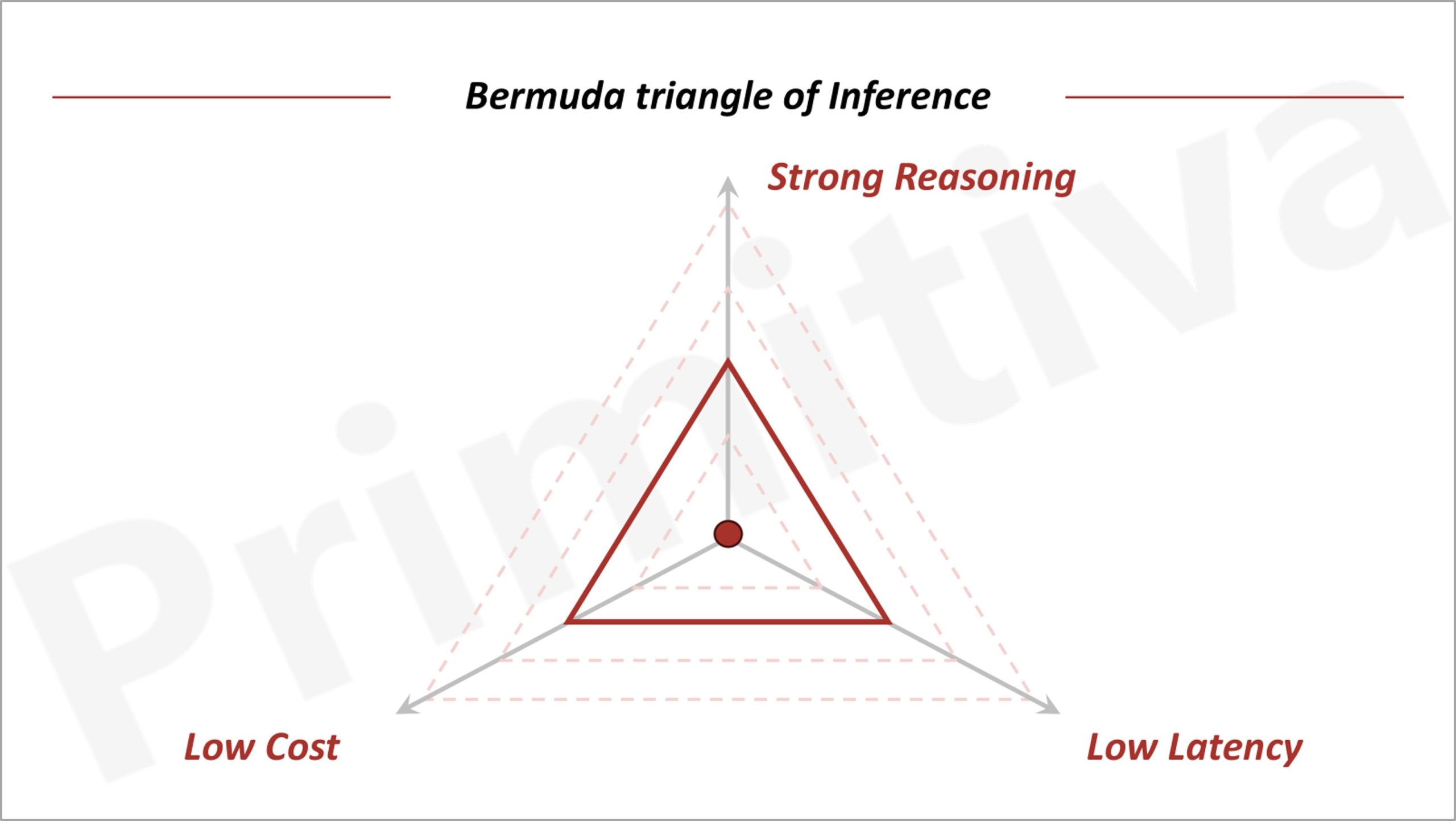
The cost surge of GPT-o1 highlights the trade-off between compute costs and model capabilities, as theorized by the Bermuda Triangle of GenAI: everything else equal, it is impossible to make simultaneous improvements on inference costs, model performance, and latency; improvement in one will necessarily come at sacrifice of another.
However, advancements in models, systems, and hardware can expand this “triangle,” enabling applications to lower costs, enhance capabilities, or reduce latency. Consequently, the pace of these cost reductions will ultimately dictate the speed of value creation in GenAI….
James Watt’s steam engine was such an example. It was invented in 1776, but took 30 years of innovations, such as the double-acting design and centrifugal governor, to raise thermal efficiency from 2% to 10%—making steam engines a viable power source for factories…
For GenAI, inference costs are the equivalent barrier. Unlike pre-generative AI software products that were regarded as a superior business model than “traditional businesses” largely because of its near-zero marginal cost, GenAI applications need to pay for GPUs for real-time compute.
Zitron is suitably cautious about his findings; perhaps some heated denials from OpenAI will clear matters up. Do read the entire post; I have excised many key details as well as some qualifiers to highlight the central concern. From Zitron:
Based on documents viewed by this publication, I am able to report OpenAI’s inference spend on Microsoft Azure, in addition to its payments to Microsoft as part of its 20% revenue share agreement, which was reported in October 2024 by The Information. In simpler terms, Microsoft receives 20% of OpenAI’s revenue….
These numbers in this post differ to those that have been reported publicly. For example, previous reports had said that OpenAI had spent $2.5 billion on “cost of revenue” – which I believe are OpenAI’s inference costs – in the first half of CY2025.
According to the documents viewed by this newsletter, OpenAI spent $5.02 billion on inference alone with Microsoft Azure in the first half of Calendar Year CY2025.
As a reminder: inference is the process through which a model creates an output.
This is a pattern that has continued through the end of September. By that point in CY2025 — three months later — OpenAI had spent $8.67 billion on inference.
OpenAI’s inference costs have risen consistently over the last 18 months, too. For example, OpenAI spent $3.76 billion on inference in CY2024, meaning that OpenAI has already doubled its inference costs in CY2025 through September.
Based on its reported revenues of $3.7 billion in CY2024 and $4.3 billion in revenue for the first half of CY2025, it seems that OpenAI’s inference costs easily eclipsed its revenues.
Yet, as mentioned previously, I am also able to shed light on OpenAI’s revenues, as these documents also reveal the amounts that Microsoft takes as part of its 20% revenue share with OpenAI.
Concerningly, extrapolating OpenAI’s revenues from this revenue share does not produce numbers that match those previously reported.
According to the documents, Microsoft received $493.8 million in revenue share payments in CY2024 from OpenAI — implying revenues for CY2024 of at least $2.469 billion, or around $1.23 billion less than the $3.7 billion that has been previously reported.
Similarly, for the first half of CY2025, Microsoft received $454.7 million as part of its revenue share agreement, implying OpenAI’s revenues for that six-month period were at least $2.273 billion, or around $2 billion less than the $4.3 billion previously reported. Through September, Microsoft’s revenue share payments totalled $865.9 million, implying OpenAI’s revenues are at least $4.329 billion.
According to Sam Altman, OpenAI’s revenue is “well more” than $13 billion. I am not sure how to reconcile that statement with the documents I have viewed….
Due to the sensitivity and significance of this information, I am taking a far more blunt approach with this piece.
Based on the information in this piece, OpenAI’s costs and revenues are potentially dramatically different to what we believed. The Information reported in October 2024 that OpenAI’s revenue could be $4 billion, and inference costs $2 billion based on documents “which include financial statements and forecasts,” and specifically added the following:
OpenAI appears to be burning far less cash than previously thought. The company burned through about $340 million in the first half of this year, leaving it with $1 billion in cash on the balance sheet before the fundraising effort. But the cash burn could accelerate sharply in the next couple of years, the documents suggest.
I do not know how to reconcile this with what I am reporting today. In the first half of CY2024, based on the information in the documents, OpenAI’s inference costs were $1.295 billion, and its revenues at least $934 million.
Indeed, it is tough to reconcile what I am reporting with much of what has been reported about OpenAI’s costs and revenues.
So this is quite a gauntlet to have thrown down. Not only is he saying that OpenAI may still have business-potential-wrecking compute costs., but his evidence indicates that OpenAI has also been making serious misrepresentations about costs and revenues. Because OpenAI is not public, OpenAI has not necessarily engaged in fraud; one presumes it have accurate with those to whom it has financial reporting obligations about money matters. But if Zitron has this right, OpenAI has been telling howlers to other important stakeholders.
The Financial Times, with whom Zitron reviewed his data before publishing, is amplifying them. From How high are OpenAI’s compute costs? Possibly a lot higher than we thought:
Pre-publication, Ed was kind enough to discuss with us the information he has seen. Here are the inference costs as a chart:

The article then correctly offers caveats, as did Zitron long form, along with kinda-sorta comments from Microsoft and OpenAI:
The best place to begin is by saying what the numbers don’t show. The above is understood to be for inference only…
More importantly, is the data correct? We showed Microsoft and OpenAI versions of the figures presented above, rounded to a multiple, and asked if they recognised them to be broadly accurate. We also put the data to people familiar with the companies and asked for any guidance they could offer.
A Microsoft spokeswoman told us: “We won’t get into specifics, but I can say the numbers aren’t quite right.” Asked what exactly that meant, the spokeswoman said Microsoft would not comment and did not respond to our subsequent requests. An OpenAI spokesman did not respond to our emails other than to say we should ask Microsoft.
A person familiar with OpenAI said the figures we had shown them did not give a complete picture, but declined to say more. In short, though we’ve been unable to verify the data’s accuracy, we’ve been given no reason to doubt it substantially either. Make of that what you will.
Taking everything at face value, the figures appear to show a disconnect between what’s been reported about OpenAI’s finances and the running costs that are going through Microsoft’s books…
As Ed writes, OpenAI appears to have spent more than $12.4bn at Azure on inference compute alone in the last seven calendar quarters. Its implied revenue for the period was a minimum of $6.8bn. Even allowing for some fudging between annualised run rates and period-end totals, the apparent gap between revenues and running costs is a lot more than has been reported previously. And, like Ed, we’re struggling to explain how the numbers can be so far apart.
If the data is accurate — which we can’t guarantee, to reiterate, but we’re writing this post after giving both companies every opportunity to tell us that it isn’t — then it would call into question the business model of OpenAI and nearly every other general-purpose LLM vendor. At some point, going by the figures, either running costs have to collapse or customer charges have to rise dramatically. There’s no hint of either trend taking hold yet.
A quick search on Twitter finds no one yet attempting to lay a glove on Zitron. In the pink paper comments section, a few contend that Microsoft making weak protests about the data means it can’t be relied upon. While that is narrowly correct, one would expect a more robust debunking given the implications. And some of the supportive comments add value, like:
Bildermann
It explains why ChatGPT has become so dumb. They are trying to reduce inference costs.His name is Robert Paulson
The fact we have to use a gypsy with a magic 8 ball to figure out these numbers for the company that is “going to revolutionize every industry” is more telling then the numbers themselvesNo F1 key
Zitron has definitely been hitting that haterade, but Microsoft press saying the numbers ‘aren’t quite right’ makes me think this is pretty accurate.
manticore
That creaking noise is the lid being prized off the can of worms –MS had better get on top of this. That income stream is highly unlikely – becoz straight line etc etc – which means that their projections are going to be badly affected and presumably there has to be a K split in the projection line at some point. MS getting holed below the waterline has real-world impacts.
Multipass
I’ve been reading Ed’s blog for a while now and while he is clearly biased in one direction, it comes across as infinitely more credible than anything Sam Altman has said in years.The real issue in my eyes is that the revenue numbers are so opaque and obfuscated that nobody has any idea if any of this will make money.
The fact that Microsoft and Google seem to be intentionally muddying the waters when it comes to non-hosting-related LLM-driven revenues and that OpenAI and Anthropic have been disclosing basically nothing should come across as a major red flag, and yet nobody seems to care.
Angry Analyst still
Spoiler alert: technology maturity will not help.They will train and train and train ever larger models (parameter count in the trillions), feeding it all the data they can get or fabricate, using more powerful supercomputers than those running the physics simulations of the US nuclear arsenal. They will manually hack (which is why they need thousands of developers) additional logic around the model, fine tuned for more and more scenarios.
But it will all just papering over the inescapable fact that a generative pre-trained transformer model is intelligence as much as CGI is reality: that is exactly zero, it’s all a crude, approximate imitation devoid of the underlying nature of the thing. GPTs, for example, cannot solve logical problems because GPT models lack the facilities to have a conceptual representation of a problem, or in themselves to hold onto any ‘idea’. That’s also why whenever you try to use a GPT to carefully fine tune a response, it mostly cannot, it will just regenerate everything even if explicitly instructed not to do so.
The important question is: does it matter?
It could very well be that the imitation game will reach a point (with all that manual hacking and testing thousands of trajectories to select and condense the most likely response during inference) where it will be able to create and maintain the illusion of intelligence, even sentience, that hundreds of millions will end up just using it anyway, regardless of accuracy or substance. There are early warning of that already.
It also stands to reason that most tech bros know this, but go along with the game because 1) it is all about relevance and engagement, there is lots of money to be made even from just imitation, and 2) most likely they believe they need to take part in this phase of AI development to be in position for the next one.In any case, there is no path for GPT towards intelligence, it is not a scaling or maturity issue.
Let us see if and when some shoes drop after this report. The bare minimum ought to be sharper questions at analyst calls.


As per the Angry Analist still comment when he makes his important question let me reframe it:
Are we willing to voluntarily fall into something like in the allegory of the cave by Plato? And pay handsomely for it? Really?
Sam Altman is selling a “sci fi dystopia”!
Shocking that no one is asking “is it feasible”! Much less “should we do it”!
Well, some people are happy to toss everyone into the cave. The BS industry (politics/PR/ads) already has a relaxed attitude to precision but a willingness to pay for customization. Relaxing accuracy to lower costs might not do enough to make a long-term, viable business but it’s something to go on with in the meantime.
Ed may be seeing numbers that are being leaked to him from someone on the inside at Microsoft (like he was apparently with Anthropic and AWS in the earlier piece) but 1) he’s just posting numbers, not the source material and 2) he doesn’t have a real understanding of what he is seeing because he is neither a software developer nor a financial person so he has to reconstruct meaning based on what he thinks he’s seeing.
I don’t think he has the full picture or understanding here (like with the Anthropic piece, where he conjectured that Cursor, a startup using Anthropic’s service, was vastly increasing their cash burn because Anthropic raised their prices, when it was clear to everyone in the industry that Cursor was developing their own models and that was why the big increase in cash burn, and this was confirmed in the week following Ed’s piece), so I am wary of taking his claims as an accurate interpretation of the whole story. I do hope and assume that the investors will be asking Altman et al pointed questions behind closed doors. I do not expect anything public to be shared.
Do I know the whole story? No, nobody is leaking stuff to me and I don’t see Azure’s billing data for the OpenAI accounts, I’m just a peon in the industry. And NB I am not in any way defending OpenAI, I’m on record here stating multiple times I think they’re unlikely to achieve any of their grandiose aims other than spending a lot of investor and potentially government money. This. from later in Ed’s piece, I agree with fully:
Massive, general-purpose models like what OpenAI makes are not the future. Small, hyper-niche models focused on very specific tasks + sophisticated context engines are the next wave and they will be far more effective and cheaper to operate than anything currently on offer from the frontier model providers. But for now, the vast majority of US/EU customers who are using AI services are contracting private endpoints through OpenAI or Azure because the GPT series is still considered the primary frontier model (because they’ve been tricked/forced by export control to avoid cheaper/better Chinese models). Those contracts are usually pay-as-you-go but the bigger companies are negotiating annual contracts for usage discounts. There probably aren’t enough companies doing useful stuff with their endpoints to spend enough to ensure OpenAI’s revenue line continues to go up quarter over quarter as Altman needs it to in order to cash out. OpenAI will fall, but I don’t think this is the death blow.
Your framing what Zitron received as “numbers” as opposed to “documents” as he and the Financial Times indicate, diminishes the information he received. It is not the full picture but is presumably accurate as far as it went.
As a finance person, I deem being a finance person to be completely overrated. “Finance people” need to be able to add, subtract, multiply and divide and master net present value, which became not difficult since the advent of the HP-12c, as in well before the introduction of spreadsheet software. Investment bankers were often humanities and social science majors. Industry professionals use a specialized vocabulary to obfuscate not-hard-to-master concepts. The sectors that take more skill are derivatives (you need to use calculus often enough to have an intuitive feel) and tax (done by tax lawyers, you have to turn your brain inside out a bit to be really good at tax).
Speaking of obfuscation: do “inference costs” have some special properties that they should differ from the “operational costs” that were taught to me in my antediluvian micro courses? Back there in the mesozoic we regularly raved about value-free neo-classical obscurantism. Please tell me that this is just a cool word used by those in-the-know, and I shouldn’t get annoyed by the seeming specialness of this entire construct.
Exactly! Inference: to carry forward. In plain speak, to use the things.
Hear, hear!, Chuck!~
its just silly…like the new word(to me, at least):”Compute”…used as a noun, i think.
reminds me of that Welch guy at GE, back in the day, right before it all came asunder…or the Enron People, in their turn at the wheel.
cheerleaders, but without the sexy skirts.
similarly to Twain’s adage to never enter a career that requires new wardrobe, do not invest in anything that has invented a new language.
meanwhile, i just wanna know how to get the linux mint OS off the damed stick and onto the harddrive, so’s i dont hafta start from scratch every time i turn the machine on.
“I say, beware of all enterprises that require new clothes, and not rather a new wearer of clothes. If there is not a new man, how can the new clothes be made to fit? If you have any enterprise before you, try it in your old clothes.”
Thoreau, not Twain.
Do you have some problems following installation guide from the home page of the Linux Mint site?
As a non financial and non AI “dolt on the street”, I get lost in the terminology. For we people it would be helpful to define some commonly used terms a bit more. I was confused by the term “inference cost”, being a fixed or variable recurrent cost. I think this link is helpful.
https://blog.adyog.com/2025/02/09/the-economics-of-ai-training-and-inference-how-deepseek-broke-the-cost-curve/
This has long been my impression of economics. My background is in physics, where I’ve really internalized the opposite drive: it’s all about reducing complex phenomena down to simple laws of cause and effect. This is how I seek to understand the world, and when I notice someone (or a whole field of people) using deliberately obtuse explanations and lingo… it’s hard to escape the feeling that they’re either 1) con men, or 2) quite dim.
On the other hand, I do think this is exactly why raspberry jam might be reluctant to trust Zitron’s interpretation of financial documents. If you’re not initiated into the argot, it might be easy to misinterpret simple things. It’s not clear to me whether FT looked at the documents with Zitron, it sounds more like they’re just amplifying his claims.
Financial statements do not require specialized knowledge or vocabulary. They are about as easy as it gets. He is also making extremely basic comparisons.
The more complicated things are valuation of companies and and structured securities or other complex financial instruments. Absolutely nada like that is happening here.
Your comment about “finance people” and basic arithmetic made me think back to an interview in, oh, early 2004, that I completely failed from Minute 1 because all they were interested in is whether I’d memorized the mathematical formula for CAGR. Which of course I hadn’t, because a) who cares, b) I can always look it up or code it into Excel, and c) I’d gotten used to computing a rough guesstimate in my head (not using the official CAGR formula), and calculating the exact figure only if I really needed to. It’s like that fixed income trading desk thing where you can roughly get to your IRR on an n-year bond based on the coupon and where it’s trading (par minus price in points divided by n years plus the coupon), it’s good enough for a convo with a trader, and if I need the down-to-umpteen-decimal-places IRR for the higher-ups there’s always Excel.
That said. There is something to be said about being read financial statements and pick out the stuff that matters versus the stuff that does not, something I have never seen any financial reporter accomplish with any degree of lucidity, but then I’m jaded and bitter like that.
More on topic. I suspect the substack guy was sent some equivalent of the monthly or quarterly mini-financial reports that lenders on a leveraged loan might get from a really cagey company. E.g. instead of the full financial statements you’d have basically four numbers in a one-page PDF. Though in this case this could be a Microsoft guy leaking whatever Microsoft gets as backup for the revenue-sharing agreement. That’s why there are relatively few details, or, at least, that’s my guess.
Even more on topic. I will bet money that if I showed this substack post to any “tech guy” (or girl) that is not middle management and up, it will confirm their pre-existing biases that are not exactly Large Language Model-friendly at the moment. Especially the softer side of IT, like the people who draft business requirements and policy docs and such, because they’ve had to deal with this stuff the most thus far, subjectively speaking.
Economists (who overlap a lot with finance) also have a history of using that line as a gate-keeping tactic to avoid arguments: “You just don’t understand the mathematics.” They kept doing that until actual mathematicians paid attention and pointed out that much of their mathematics was actually wrong (even if the underlying assumptions that made it applicable were valid, which they weren’t).
Krugman was a big offender for a while. He stopped doing it once the mathematics started getting enough scrutiny to be embarrassing.
Who would have thought that inference costs would surpass training?
Any video gamer could have told you that running kW GPUs to compute stuff doesn’t come cheap. The AI model is based around running hardware for immersive 3d simulations at full tilt for 30 seconds at a time to make 1kb of text. I fail to grasp how this will ever be sustainable.
Especially when all the chips have to be replaced every three to five years.
Even three years is a stretch.
Overheating Issues with NVIDIA Chips
Performance Under Load
NVIDIA’s latest AI chips, particularly the H100 Tensor Core GPUs, have been reported to overheat during extended high-performance tasks. These chips are designed for demanding applications like generative AI and machine learning, which can push their thermal limits.
Causes of Overheating
High Power Demand: NVIDIA chips are known for their energy-intensive operations. When used in data centers that run 24/7, they can generate significant heat.
Complex Data Models: Modern AI models are increasingly complex, requiring more processing power and leading to higher heat generation.
Cooling Infrastructure: The effectiveness of cooling systems in data centers plays a crucial role. If these systems are not well-managed, it can exacerbate overheating issues.
NVIDIA’s Response
NVIDIA is aware of these challenges and is in discussions with partners to improve thermal management solutions. They emphasize that proper cooling infrastructure is essential for maximizing GPU performance in data centers.
Market Impact
While overheating could affect the reliability of NVIDIA’s chips, experts believe the company will maintain a strong position in the AI chip market due to its technological advantages. However, data center operators may face increased costs to implement adequate cooling solutions.
Talking to Nvidia GPU engineers some 20 years ago, the life limitation was due to metal migration of on-die conductors. Essentially, metal atoms would move with the electron flow thinning the track at one end until failure. Back then, I was told a GPU would last 10 years running at full thrash/temperature. So 3 years with the much, much smaller geometries now makes sense to me.
Yeah, Satya (MSFT) was on a AI booster podcast this week and this is a clip of him talking about this.
https://x.com/RihardJarc/status/1988963106215841865
I think those in the industry are gleefully thinking “these are great problems to have!!”. Demand for inference is so high that OpenAI is spending billions on inference! Engineers are designing datacenters to squeeze more life out of older H100 GPUs!
Two to three years is what Michael Burry was quoted as saying in Business Insider in yesterday’s Links.
https://www.businessinsider.com/michael-burry-ai-stocks-nvidia-meta-oracle-hyperscalers-jim-chanos-2025-11
Elsewhere here I ready that hyperscalers are fudging their numbers by choosing too-long amortization times for the HW.
Michael Burry has just called out the AI hyperscalers for tweaking their depreciation schedules to artificially inflate earnings. The link below includes a chart showing how the big names like META, GOOG, ORCL, MSFT, AMZN are stretching out the useful life of their assets.
https://thedeepdive.ca/burry-warns-tech-depreciation-changes/
Also, in Zitron’s piece, he states that based on the apparently inaccurate revenue reporting,
I’m not a financial expert, but that doesn’t sound very good to me.
Regarding railroads and the dot com bubble, I think the crucial thing is who is willing to pay enough to keep running the AI-centers after the bubble bursts, with the high costs Zitron has found?
I think the general public won’t, as is seen in current prices.
Some corporations might, if they think they can re-coup the costs and more by replacing employees. If the company is oligopolistic enough that it can force the customers to accept the crappy products, they might get away with it.
The US military is awash in money and AI is a great accountability sink. As long as you don’t care that you murder random people – and the US military evidently doesn’t care – having AI find the targets and do the murder can be worth a lot.
The surveilliance state is currently having the problem with massive hay stacks where needles are hard to find. AI may not find needles, but it will claim to find them, and that might be good enough as long as they are within “the usual suspects”. The purpose of a pre-crime unit is after all to control through fear. Fear doesn’t appear to work in the long run, rather it creates pressure and one day it explodes. But you know what Keynes says about the long run.
I think you are on the money here. The purpose of a system is what it does, and what AI is doing is funnelling massive amounts of wealth into building up massive compute resources. After this bubble blows, who is going to be using those resources
The money isn’t coming back. But the compute will still be there, and cheaper, at least for the 5, outside 10 years of the hardwares usable lifetime.
I tend to think the datacenters themselves, and network infrastructure, plays the role of railway track. The computers, GPUs, racks, something closer to railway engines and cars. The software running on them bring the cargo and passengers.
Who needs this much processing on demand over the next 10 or so years?
How are they going to cool these things when the water is gone, or greatly diminished in quantity and quality? Water isn’t going to be cheap, and the parched neighbors aren’t going to be indifferent to their water going away.
Rails and fiber optic lines had/have minor O&M costs compared to data centers.
The chips need to be replaced after 3 years, so they will need to constantly be rebuilding with expensive chips. There won’t be leftover infrastructure.
AI (or crypto) is not the only thing you can run on these GPUs, there is a lot of simulations and general computing that wants to be done at the right price.
No that is not correct. Please do not misinform readers. I can’t readily find a non-geeky source, but these chips are suited only for comparativey narrow uses.
This article is over my pay grade but some key points:
https://machine-learning-made-simple.medium.com/the-flops-fallacy-why-silicon-valleys-compute-strategy-is-dangerously-obsolete-1e1e33ca1fcd
I bet they could be reconfigured for climate modeling compute. Most climate models are simple finite difference with the next door neighbors. What eats up the CPU is there are giga giga giga grid nodes.
These chips aren’t general purpose in the same sense normal CPUs are, but what this means is they are specialized at massively parallelized computing. Essentially they have many small CPUs that are individually slower than full blown CPU, however if you can divide your task into smaller packages that can be computed separately and then aggregated at next stage, the speed up is immense. Obviously not all tasks fall in that category, but a lot of them do, and AI is only one of the many. Latest iterations of these chips may have some tweaks to cater to AI, but they are things like additional instructions or higher memory speeds, at the core they are still the same chips that can also run tasks like 3D rendering or fluid simulation.
So for example here is list of US supercomputers, you will note the last column has the GPU used in the configuration, and very often it’s NVIDIA.
It’s mainly going to be crappy services – especially govt and education.
Places where people can be forced to interact with and tolerate this BS.
It’s a middle man power play and everyone will rue the day.
They paved over paradise and put up a parking lot.
jm
And we’ve got to get ourselves back to the Garden.
jm
Caught a few minutes of Bloomberg news 12 Nov evening. A commenter there said something along the lines of ‘how the market may worry about hundreds of billions of capitalization and 10’s of billions (he was overstating) in revenues……’
That observed there are smart people working the SW and HW revolutions against big LLM, high heat AI!
Great piece. I’d just add a small tidbit to corroborate this point:
The fixed capital built by the AI spending mania has extremely low lifespan: a recent study by Meta’s AI research team noted that
Which is to say, they burn through professional-class GPUs like nobody’s business. Once these AI business go belly-up, the only legacy to posterity they’ll potentially leave is some big climate-controlled buildings.
Great places to grow weed.
so…homelessness will be solved, at last!
Wouldn’t it be something if, while this grifter is running the bezzleship straight at the iceberg, other countries were serious about developing ai applications relevant for national security?
The current western state of AI is Automated Insatiability. Neoliberal doctrine in concrete material form.
Let’s not overthink this. It is an order of magnitude and direction game. OpenAI is discussing a historic level of spend and can’t concisely tell you how the economics could possibly work, and where the money is coming from.
The crime, if you can call it that, is all the enablers in government and on Wall Street. Neither will speak the truth. In the case of government because they see this as propping up the economy and their tech donors, and if, say China, figures it out and we don’t they will get blames. On Wall Street, when there is a capital raising wave they salivate over all the fees .
The enablers in government and on Wall Street are not much more capable of understanding the technology than my dog, in most cases.
Like my dog, though, they do understand food treats — or in their cases, money payoffs.
The purpose of the Western AI plays is to restore “cathedral” style computing and information control in order to become the Trust and Safety department of all technological society, and they do this by playing both the utopian and doomer camps to achieve the goal. Both camps are full of emotion-addicted suckers and drama addicts.
China’s open-source AI plays pull the world in an opposite direction: here are the weights, infer them on any GPU you like, even the one in your own PC. It’s a regulatory play, like Uber: OpenAI and Anthropic are only worth anything if they can enforce their cloud-metered model as the normal way. But for some reason, nobody seems to want to talk about the meta game (as it were) here.
Ah, the cathedral, top down point is interesting. Wil need to give that a further think.
Recall part of the data centre deals on other countries involve scrapping non-US telecoms tech(Huawei) and installing the likes of Cisco instead.
Another aspect of the infrastute boom is that the US ends up owning the cathedral.
bingo!
ironically (not really), China is Princeß Leia, and Silicon Valley are Moff Tarkin & Co.
The Chinese are not the only ones to release open weight models. Mistral (French) and Facebook (AKA “Meta”) both primarily release open weight models; my read is this is their best avenue to stand out and get recognition. OpenAI does release some open weight models, but they are of course deliberately much smaller and less powerful than their proprietary flagships.
I knew OpenAI’s economics were dodgy when I was an early paid subscriber and 2-3 months into it my subscription was revoked, for no reason or explanation given whatsoever. It’s like my name was suddenly on a hidden “do not subscribe” list and I’ve been blocked from subscribing ever since. T
Bottom line is where there is no accountability or transparency on the numbers or business or policy side, it’s suspect regardless.
(Not to worry, I have my ways around it.)
Two inexorable laws from my computer days which are routinely ignored when inconvenient, leading to failure, and which seem pertinent to AI development are: “Good, fast, cheap. Pick any two.” and the venerable “GIGO: Garbage In, Garbage Out.” Also borne out by Robert Urie’s excellent analyses, which include differentiating between industrial and internet AI, they seem especially relevant to the development of AI as it is being carried out by US techies whose holy grail seems to be to monetize and monopolize.
I expect that the most powerful application of AI going forward will be for military applications and porn, and of course, for narrative control and “manufacturing consent.” I predict that generative or “internet AI” will not die, despite crippling contradictions, because governments and corporate entities want it for propaganda purposes. I believe it is also Rob Urie who suggested that AI stands not for “artificial intelligence” but “artificial information.” Spot on.
The tulip stem is rotting and its bulb is full of maggots.
AI has taught me how difficult it is to convey ur thoughts with language. I suspect larger the model it will find more ways of interpreting instructions thereby making alignment even more difficult. Another pit fall is after tediously teaching AI what a program does,it forgets everything next day.. loss of context is a killer
Human intelligence has many aspects: logic, emotion, intuition, judgement, and physical. AI is based solely on logic, on mathematics. There’s a branch of philosophy call Epistemology. Epistemology the branch of philosophy that examines the nature of knowledge, its presuppositions and foundations, and its extent and validity.
There is no epistemology for AI as far as I know. There is only high-level mathematics that can produce “hallucinations”, and nobody knows why that happens.
“Hallucination” is the name AI supporters give to any result they don’t like. For the LLM, all results are hallucinations, but some happen to match what we expect more closely.
I worked in telecom during that bubble period and I can assure you that in my opinion, all bubbles come with some accounting shenanigans.
And I have to say it hadn’t occurred to me that inference costs could be exponential, but it does make sense in hindsight. Just about any significant accuracy improvement for any data models comes with increased complexity. That increased complexity also comes with increased computational demands.
The bubble of size that I watched unfold with rapt interest was that of numismatist Bruce McNall, who at the height of his empire of sorts, owned the LA Kings, a Hollywood studio, a top rank thoroughbred stable and the Toronto Argonauts as a nice topping.
The coin biz was a good living for those pushing old metal around, but it was nothing like that where you could own all of those assets, especially since McNall’s specialty was ancient Greek and Roman coins, hardly a moneyspinner in the scheme of things, more along the lines of numismatists who wore tweedy coats and can tell you more about the various imperial mints of Tiberius than you might want to know.
When the bubble was rolling, major banks gave him major loans based upon his bonafides, and without much circumspection regarding the collateral.
As the bubble was unraveling late in the game, the banks were getting awfully squirrely in regards to monies lent out, and in one case they’d loaned $25 million for sports memorabilia, and wanted to see it, so over the course of a couple days, McNall’s minions spread out all over LA and OC buying ‘commons’ baseball cards from sports card stores for 2¢ each, which was double the going rate at the time, and commons were called common for a reason, and they bought a veritable shitlode and rented out a warehouse filled up with boxes of said commons, and the appraiser was wowed by size, and peril passed for a time.
And then another bank got cold feet over rare stamps that they’d loaned out $20 million on, and I knew a coin dealer who was a rare switch hitter in that he knew stamps as well, you almost never saw that in the biz.
He got called by the bank who needed an appraisal and QUICK!
Said appraisal was duly done and he got up to about $17k in fair wholesale value, and asked where the rest was, knowing the amount loaned.
Jimmy Dore rips on the big tech AI welfare kings. Talking about Altman specifically. utube.
Open AI’s Sam Altman ALREADY Looking For A Government Bailout!
https://www.youtube.com/watch?v=beDspJEBa1Y
I don’t mean to seem harsh, since you provide many fine comments.
Dore is very late to this party. And I am generally not keen about him but have held my tongue so far. I don’t find him to be insightful or otherwise value added. He seems to have fallen between two stools, of trying to do commentary and comedy, and IMHO he’s not that hot at either of them. Some critics can get away with being slow to jump on hot news because they have a great turn of phrase or add imporant detail or analysis. I don’t see that from Dore.
Gary Marcus warned of this 10 months ago.
There were tons and I mean tons of video clips of Altman’s begging and unsympathetic takes on Twitter a week ago.
We told readers to call their legislators then, as in a full week ago: Call Your Congresscritters: OpenAI Laying the Groundwork for Massive Federal Bailout
See YouTuber, Meet Kevin with a trading oriented channel with a not teeny following: OpenAI **just** begged for a *Government* BAILOUT!
And for a more mass audience, Breaking Points two days ago: Sam Altman FREAKS At Bubble Suggestion, Demands Bailout
Thanks much for the links.
“how difficult it is to convey ur thoughts with language”
Precisely! The hidden springs of discovery in all art and science are real but ineffable and will remain so for the duration.
In my world medical students have discovered that ChatGPT or equivalent can make tables from medical texts of all kinds. Of course, the connections are hidden from them and will remain so and their newfound “knowledge” will decay exponentially. Look forward to them using their phone to diagnose your condition, while leaving out the healing part of medicine. It is also clear that the best medical students still read, study, and master the foundations the old fashioned way. But that seems to be only 10-15% of them…That AI/LLM made a perfect score on the first medical board exam (USMLE Step 1) is no more or less impressive than Deep Blue winning a chess match against Gary Kasparov, almost 30 years ago.
It took me a long time to master the composition version of eye-hand coordination, and even now I sometimes stuff up. I got a very big boost from my sophmore tutorial, two whip-smart grad students to five of us. Most weeks we had to write a short paper. They woud regularly come back with more in comments from each tutor than I had written. But it did teach me how to see what my sentences actualy said, as opposed to what I had wanted them to say.
re: “In my world medical students have discovered that ChatGPT or equivalent can make tables from medical texts of all kinds. Of course, the connections are hidden from them and will remain so and their newfound “knowledge” will decay exponentially.”
So, ChatGPT is the modern, digital version of the old Cliffs Notes. / ;)
If the inference cost-revenue ratio is high enough then OpenAI has serious vulnerability. A well-funded adversary can bankrupt them.
OpenAI’s play, to reach a monopoly rentier position first by massively scaling its GPT deployment faster than the competition, may compound the vulnerability. It is basically betting that its improvements in enlarging the Bermuda triangle by scaling more and faster than anyone else will make its prompt responses so much more valuable in client applications than any other service and it will thereby crush competition.
But what if the marginal improvements in enlarging the triangle vary rather worse than than linear with cost? Then, for example, China could support lots of smaller Darwinian domestic AI ventures while buying a lot of inferences from OpenAI.
OpenAI *can’t* reach a monopoly rentier position while users can pick free open-source ones instead.
It could if scale gave an unassailable quality/cost/latency advantage. It doesn’t appear that’s the case hence yes, you’re right. It turns out OpenAI has been selling something akin to what, back in the dot com bubble days, we used to call vaporware.
OpenAI fails to scale in at least three ways that I can count. 1) Each version is trained on more AI slop that the previous. 2) Adding parameters and tokens is already in a zone of diminishing returns. 3) The more sales they make, the bigger the losses.
raspberry jam has often commented here at NC that models trained on well-prepared data and applied to problems of specific limited scope can work quite well. I should think they are also very much easier to test, i.e. verify, which again supports your point that many (most) business customers don’t need OpenAI.
Will China have a lead in AI like it has in Rare Earth Element processing?
OpenAI has no monopoly and in fact is in danger already from DeepSeek, a Chinese developed AI “model”.
Per Wiki DeepSeek training costs 6% of GPT 4 training, and its compute load is 10% of Meta’s Llama 3.1.
Why Trump wants a trade war! Rare earths obscuring AI losing?
Musk getting in will lead to language models and more efficient hardware he may get close to China and Russia.
OpenAI is building cathedrals with the relic: GPT-4.
Do y’all think that the fed will just bail them out indefinitely?
Since the 2008 GFC, all the bubbles are bailed out, no, and investors saved?
The arithmetic of expanding compute load must be matched against the arithmetic of Moore’s law advances. The progress of AI will be governed by this calculation. With quantum computing on the horizon, many variables may change. Worst case, advanced AI will be rationed by pricing, and many investors will lose money, but AI will still be an epochal advance in the history of technology.
Well the “AI” I just used caused me to waste ten minutes of my time chasing a wild goose. And because it doesn’t work properly, I’ll get to do that again very soon!
I do not share your rosy outlook at all.
me neither, in theory, self driving cars will work great in the snow
Real quantum computing is waiting on supersolid light out of Darmstadt…….this might take a while.
Quantum computing would be utterly useless for LLMs.
Moore’s law ended at least a decade ago. GPUs managed to extend it some by using a different computing model, but they’ve reached the limit of that now – and the chips can’t really get any smaller (due to both quantum and heat effects). There are probably some improvements to be got, but they’re going to be much smaller (and far more expensive).
The other side to this that people don’t comment on, is that the lifespan of chips goes down as you squeeze more ‘compute’ out of them. If you’re constantly running the cutting edge GPUs you may not even get 2 years out of them.
It is interesting to think about what might be driving this large increase in inference costs. ‘Inference’ is really something of a misnomer – these models aren’t performing logic, assessing propositions, reaching conclusions or anything like that. They just take a big block of text (consisting of the user’s input plus some prior context) and spit some text out. It appears that ‘inference’ is the name used for this process, which is incidentally an example of how language is used to imply that the models are doing more than they actually are.
One of the fundamental weaknesses of LLMs is that they don’t have long term memory in the way humans do. If it exists in the input context, they know it (or their training data, but that’s generic and not specific to the individual case). If it doesn’t, they have no idea. A few paragraphs to a few pages of context is perfectly fine, but the computing power required increases non-linearly with context window size (not sure if it’s exponential, but it’s definitely at least quadratic). Reading a whole novel or textbook and remembering it is way outside their capability. This is why if you have a long interaction with an LLM-based AI, you’ll sometimes notice it ‘forgetting’ things that you talked about early in the conversation: it’s because it’s storing the conversation history in the context window, and it ran out of space to hold all of it. This is a basic constraint of the type of model used for AI. You can’t simply tell it to go and read a book and answer questions about it, the way you could with a human.
People have tried different methods to get around this. One technique is to order the AI to summarize content that it’s about to forget, then feed the summary back into the input context and progressively add to it over time. This tends to give poor results, since it involves the AI consuming AI generated content over multiple iterations. The other approach is to simply add computing power and lengthen the context window. Given enough compute, you can extend it to be very large (not quite novel length still, but close) and give the LLM much greater ability to remember. However, this gets very expensive to run very quickly. Companies have to charge a premium for it, and you won’t find this tactic in the free tier of any model.
Most of the big AI companies like OpenAI have zero transparency on context window size and how they manage it (the ‘prompt’ behind the scenes). One possible hypothesis to explain what Zitron is seeing is that OpenAI is attempting to mask fundamental limitations in the algorithm by throwing compute at the problem and increasing the context window to very large (and expensive) sizes. This is just kicking the can down the road and will eventually fail to deliver the progress they are promising, but it could preserve the appearance for a while longer. If they were doing this, we’d expect to see a large rise in compute costs over time relative to revenue – which is exactly what Zitron seems to be highlighting.
This is very helpful, thanks a lot!
Is China’s (FOSS) open source Deepseek legal for US corporate entities to use on a US datacenter? How about US corp entities using it on a non-US datacenter?
My understanding is that Corp America used or used/added to versions of UNIX & Linux for their own business purposes. Apple’s OS for their consumer computers & phones is based on UNIX.
I read that Deepseek has similar quality models to the leading propietary US vendors, but cost 30X less in CPU resources to operate.
Is some of Corp America using Deepseek, or their own customized-version of Deepseek, for business purposes?
Our wunderkind won’t get to recite, “I am become Death”?
Can AI companies survive long enough to reach the “laser in every DVD player” phase, or will they burn out in the “massive laboratory laser” phase? DeepSeek’s strategy looks more like: “Let’s make the laser cheaper first, then find applications” OpenAI’s strategy looks more like: “Let’s build the most powerful laser possible and assume applications will come”