By Lambert Strether of Corrente
This is important work by Ferguson and his colleagues, Paul Jorgensen, and Jie Chen, and especially relevant to the 2016 election. From the executive summary at iNet:
Social scientists have stubbornly held that money and election outcomes are at most weakly linked. New research provides clear evidence to the contrary.
Thomas Ferguson, Paul Jorgensen, and Jie Chen reveal strikingly direct relations between money and major party votes in all U.S. elections for the Senate and House of Representatives from 1980 to 2014. Using a new and comprehensive dataset built from government sources, they find that the relationship between the proportions of money spent by the winning party and votes is close to a straight line.
(Here is the PDF of the full paper, How Money Drives US Congressional Elections, Thomas Ferguson, Paul Jorgensen, and Jie Chen, Working Paper No. 48, August 1, 2016.) First, I’ll look at the dataset. Then, I’ll look at that “straight line” relation. Finally, I’ll look at some of the political implications of Ferguson’s work for thinking about 2016.
The Dataset
If you are a data person, and especially a big data person, Ferguson’s project is thrilling. Most everyone will be familiar with the problem of determining whether “Mr. Bob Smith, 1234 Your St., Anytown USA” and “R. Smith, Yore Avenue, Anystate” are really the same person; there’s a whole industry built up to work that stuff out because marketers (and debt collectors) need it. How much more complex when the names and addresses are entered by people with every incentive to conceal their identities! From the full paper (pp. 8-9):
For this paper, the thornier data problems arise from the fragmentation of reporting sources and formats – whose chaotic realities are, we are sure, a major reason why progress has been so slow in understanding campaign finance. Because we have extensively discussed elsewhere the measures we have taken to overco me these problems, our discussion here will be summary.
The guiding idea of our Political Money Project is to return to the raw data made available by the FEC and the IRS and create a single unified database containing all contributions in whatever form. This is a tall order, as anyone with any familiarity with our vastly different data sources will realize. In particular, FEC sources are sometimes jarringly inconsistent; many previous analysts do always appear to recognize the extent of the “flow of funds” anomalies in this data. And not all the IRS contributions are easily available in electronic form for all years.
But our real work commences only once this stage is completed. At both the FEC and the IRS, standards for reporting names of both individual and corporate contributors are laughably weak. Both companies and individuals routinely take advantage of regulatory nonchalance about even arrant non-compliance. Along with an enormous number of obviously bad faith reports (such as presidential contributions listed as coming from individuals working at banks that were swallowed long ago by other giants) all sorts of naïve, good faith errors abound in spelling, consistent use of Jr., Sr., or Mr., Ms., and Mrs., along with many incomplete entries and hyphenated names. Many people, especially very wealthy contributors, legitimately have more 9 than one address and fail to consistently list their corporate affiliations (“retired” as a category of contributor is extensively abused; some people who chair giant c orporations claim the status).
From the outset we recognized that solving this problem was indispensable to making reliable estimates of the concentration of political contributions. We adapted for our purposes programs of the type used by major hospital s and other institutions dealing with similar problems, adding many safeguards against tricks that no medical institution ever has to worry about; all the while checking and cross-checking our results, especially for large contributors. In big data efforts , there is never a point where such tasks can be regarded as unimpeachably finished. But we are certain that our data substantially improve over other sources on offer, including rosters of campaign contributions compiled by for-profit companies and all public sources.
Because we can compare many reports filed by people who we recognize as really the same person, we are able to see through schemes, such as those encouraged by the Obama campaigns (especially in 2008)[1], that encourage individual contributors to break up contributions into what looks like many “small” donations. We are also able to fill in many entries for workplace affiliation left blank. By itself, these steps lead to a quantum leap in the number of contributions coming from the same enterprises. But we have also used business directories and data from the Securities and Exchange Commission to pin down the corporate affiliations of many other contributors, whose identifications, once established, are similarly extendible.
Again, I can’t stress enough how excellent and important this work is. And it’s really hard to do!
The “Straight Line” Relation
Now let’s jump straight to the conclusion (full paper, page 10):
Data compiled like this allows us to brush past artificial efforts to distinguish kinds of spending in Congressional races, such as “inside” vs. “outside” funds (that is, spent by candidate’s own committee or by allegedly “independent” outside groups) or the spending of challengers or incumbents. Instead we simply pool all spending by and on behalf of candidates and then examine whether relative, not absolute, differences in total outlays are related to vote differentials.
If conventional claims about the limited importance of political money are correct, then the individual data points – particular House or Senate election outcomes – should be scattered indifferently across the graph. Money just wouldn’t predict voting outcomes very well. If on the other hand, money is strongly associated with votes received, then the fit would approximate a straight line. All kinds of intermediate cases, of course, can be imagined.
And here are those straight lines:
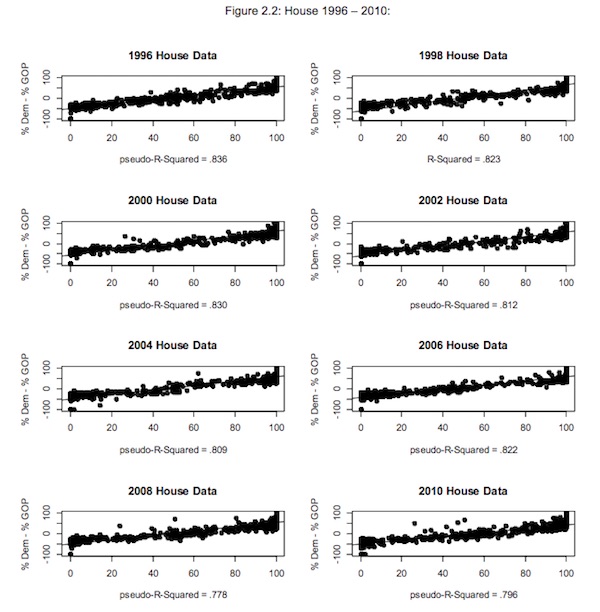
(These table is an excellent example of the power of Tufte’s “small multiples.” Readers who are clever about statistics (and I am not) will have objected that Ferguson’s methodology may not be able to tease out money as an effect from money as a cause, to which Ferguson et al. respond as follows:
[T]here is one last redoubt in which skeptics can take refuge: the possibility that money and votes are reciprocally related. AsJac obson artfully frames the conundrum that protects this escape hatch: “Money may help win votes, but the expectation that a candidate can win votes also brings in money. To the degree that (expected) votes influence spending, ordinary measures will exaggera te the effects of spending on votes.”
Our response to this challenge consists of two parts. Firstly, at least one clear natural experiment exists, in which it is possible to say with reasonable certainty that a tidal wave of money helped produce a sho cking political upset that was anticipated by scarcely anyone: The famous 1994 election in which Newt Gingrich and a Golden Horde of donors stunned the world by seizing control of the House of Representatives for the Republicans for the first time since 1954 (and only the third time since 1932). Taking a leaf from recent studies in economics and finance of event analysis, we use published estimates of the change in the odds of a Republican takeover to rule out appeals to confident expectations of taking over the House as the explanation for the wave of money that drowned House Democrats that year.
But 1994 is only one case, though admittedly a momentous one. We have not been able to locate usable odds compilations for other elections. In the hope of bypassing tedious debates over a host of less clear cut cases, we searched for more general approaches. … We suspect that where politics and money is concerned, the search for good instruments is in most instances akin to hunting the Snark. A better approach is to search for estimation methods that do not require us to lean so heavily on thin reeds. This quest led us to the work of Peter Ebbes and his colleagues. Ebbes and his associates have developed latent instrumental variable (LIV) models into a practical working tool, where the instrument is unknown, and used them to attack a variety of problems.
These methods are relatively new and, of course, like virtually all statistical tools, rely on assumptions for their validity, but the assumptions required do not appear any more farfetched than more conventional approaches to tackling the question. Irene Hueter’s recent critical review is very helpful in clarifying important points. While critical on various secondary issues, she concludes that the method appears to be fundamentally sound and to work in practice: the solutions it gives to some classical econometric applications appear reasonable and in line with results using more traditional methods. We think it is time to try the approach on money and politics, particularly since we can crosscheck its findings with our results on 1994, obtained by the completely different approach now conventional in finance.
Personally, I have to accept Ferguson’s authority on this, but the Naked Capitalism commentariat being what it is, perhaps readers will be able to comment on the “latent instrumental variable” approach.
The 2016 Election
One more conclusion that Ferguson et al. draw is that yes, we do live in an oligarchy (although factional conflicts take place among oligarchs:
We demonstrated, for example, that the 1% — defined quite carefully – dominated both major parties; at the same time, however, our results once again directly confirmed the huge differences in the extent to which specific sectors and blocs of firms within big business differentially support Democrats or Republicans. The results point up the futility of trying to underst and the dynamics of American politics without reference to investor coalitions and strongly support a broad investment approach to party competition. We showed that the case of the Tea Party was no different by tracking the rates of support for its candidates within business as a whole but, most importantly, within big business. Claims that major American businesses do not financially support Tea Party candidates are plainly false.
I’m not sure whether Ferguson’s results for House (and Senate) races translate directly to Presidential races. However, it would seem to me that at least in 2016, the relationship between money and electoral success has not been linear. After all, how much did George Bush blow? $270 million? And while Clinton is far better funded than Trump, it’s not at all clear that she’s getting any kind of bang for the buck. Perhaps candidate quality is a wild card at the Presidential level.
NOTE
[1] Well, well. I remember raising this issue in 2008, and being scoffed at. It would be interesting to know if the same techniques were used by the Trump campaign, which just came out with a small donors story, and, to be fair, whether they were used by Clinton or even Sanders.


The Clinton campaign’s tactics to inflate the small donor numbers are apparently to just bill their small donors over and over again. Typical democrats: screw over your poorest supporters (in all fairness, Republicans are good at that trick too).
http://www.kare11.com/news/investigations/kare-11-investigates-unauthorized-charges-by-clinton-campaign/229158541
I think it is rigthly arguable that the relation between money attracted and voting outcome can be reciprocally related. In the case that a candidate is seen as a potential winner, it can attract money that “wins” the rigth to be heared after the election. In other words, to make the candidate friendly to the interests that money represents. This is backed by the fact that the most powerful contributors finance both candidates (the two candidates that have real chance).
Anycase, this study very much supports Greg Palast’s book title. Money has a clear effect in election outcome, and almost certainly an even bigger effect on policy, after the election. Good job indeed!
“And while Clinton is far better funded than Trump, it’s not at all clear that she’s getting any kind of bang for the buck. Perhaps candidate quality is a wild card at the Presidential level.”
The Dollary Clump Campaign is likely to screw up a lot of models, its already turned satire from a form of critique to a form of government reducing important propaganda organs to pathetic persiflage in the process.
The sleuthing required for this effort is amazing, as anyone who has tried to research campaign spending knows, and Ferguson et al are to be highly commended for their effort to shine more daylight on the sordid side of American democracy.
But about that oligarchy. Why not share that information? If the data has been aggregated to individuals and corporations can they be ranked and listed for the world to see? Can Ferguson et al at least share with us a glimpse of who is actually controlling the levers of power in our democracy as it sure isn’t the people.
About a year ago, there was an article in the NY Times with a list of the 158 families who are supposedly donating the most to the Presidential campaign. This list has some major gaps, since the Koch family, the Walton family, and the (Sheldon) Adelson families are not on it. Also, it’s in the NY Times, so if you don’t want to use up your monthly allotment of articles, link to the article from an incognito or private browser.
http://www.nytimes.com/2015/10/11/us/politics/wealthy-families-presidential-candidates.html#donors-list
There’s also this web site by G. William Domhoff:
http://www2.ucsc.edu/whorulesamerica/
The 7th edition of his book Who Rules America? is available, and it has a list price of about $110.00. A loose leaf version can be had for a steal, only about $80.00.
Or go into your browser & clear the NYT cookies. This will reset your monthly “count” to zero.
If you are not ignoring the New York Times, you are part of the problem.
I wanted to ignore them; I tried to ignore them! I remembered that there had been an article about 158 rich families, so I a web search. After looking at 6 or 7 articles, all of which were fairly short and just linked to the NY Times article, I declared victory, gave up, and looked at the NY Times article, which is the only place where I could find the actual list.
I actually meant to add that. It would be nice to have an API to the data, for example, even if it isn’t all available as a CSV (and there could be lamentable but legitimate funding reasons for that).
Yes and no — sorry, but at this point in time it isn’t really important, we all know Wall Street owns the government, we know where those crapweasels comes from at the Department of Treasury, and Justice, and State (we know that the CIA within the State Department, which the Kennedy brothers once attempted to eradicate, has been incredibly strengthened by Hillary Clinton when she was secretary of state by her hiring all those former CIA types), etc., etc.
We know this stuff already, and those of us concerned enough have read David Dayen’s masterful book, Chain of Title, and realize that Covington & Burling’s point man, Erick Holder, was appointed by Obama so the MERS criminal conspiracy wouldn’t be uncovered and the banksters wouldn’t be criminally prosecuted as they should all be!
Old news, chum, sorry . . . .
It’s not news, “chum,” it’s an academic study.
The part that I didn’t look at — and I need to look at more of Ferguson work — is how he uses aggregations of funders to outline elite factional conflict (otherwise obscured by the “bad” record keeping) in the donor class, i.e. the 1%. That’s very useful, pragmatically.
re: “I’m not sure whether Ferguson’s results for House (and Senate) races translate directly to Presidential races. However, it would seem to me that at least in 2016, the relationship between money and electoral success has not been linear. After all, how much did George Bush blow? $270 million? And while Clinton is far better funded than Trump, it’s not at all clear that she’s getting any kind of bang for the buck.”
Spending levels and Presidential campaigns often do NOT correlate directly for a simple reason: Presidential elections are one of the few political contests in which “free media,” i.e., coverage in the news media, TV, blog commentary, Twitter, etc, compensates and often overwhelms the advertising and organizational effects of the campaigns themselves. Thus, Trump has so far received news media coverage worth at least a billion dollars in paid advertising. Further, Jeb, Trump, Clinton are known commodities to the general public. Bernie was an interesting phenomenon. In the end, of course, his fundraising was quite respectable. But in the beginning he benefited from another factor. There was a large latent pro-change anti-Clinton constituency in the Democratic Party hungry for a hero. Presidential primary campaigns are long. There was time for the news to get out and word to spread. Once the latent anti-Clintonites realized they had a candidate, they gravitated to him, which generated more attention and more money…Finally, there are always exceptions in any data set. Over the years there are numerous examples of Congressional candidates defeating better funded opponents, especially in primaries, where turnout is small. Such exceptions do NOT disprove the general rule. It has always been a rule of thumb among practicing political professionals that the bigger your candidate’s funding advantage, the better your chances on election day. Ferguson has proved what common sense and practical experience tell us.
Ferguson says explicitly that the linear correlation in Senate races is choppier (I forget the exact term of art) and one reason is media. So that makes sense.
And makes independent media all the more important…
Well, then could not one conclude that the Supreme Court was wrong in declaring money to be a form of protected speech? According to this study, money isn’t speech, it is votes. And if that is true, then the Supreme Courts rulings violate the “one man: one vote” principle. The number of votes a person has is now determined by his/her wealth and how much of it they are willing to buy an election with.