By Philip Pilkington, a macroeconomist working in investment management. He is the author of the book The Reformation in Economics: A Deconstruction and Reconstruction of Economic Theory which will be published by Palgrave Macmillan in December 2016. He used to run the blog Fixing the Economists (now closed). The views expressed in this article are the author’s own and do not reflect the views of his employer.
The election of Donald Trump as president of the United States will likely go down in history for any number of reasons. But let us leave this to one side for a moment and survey some of the collateral damage generated by the election. I am thinking of the pollsters. By all accounts these pollsters – specifically the pollster-cum-pundits – failed miserably in this election. Let us give some thought as to why – because it is a big question with large social and political ramifications.
Some may say that the polls were simply wrong this election. There is an element of truth to this notion. The day of the election the RCP poll average put Clinton some three points ahead of Trump which certainly did not conform to the victory that Trump actually won. But I followed the polls throughout the election and did some analysis of my own and I do not think that this explanation goes deep enough.
I have a very different explanation of why the pollsters got it so wrong. My argument is based on two statements which I hope to convince you of:
- That the pollsters were not actually using anything resembling scientific methodology when investigating the polls. Rather they were simply tracking the trends and calibrating their commentary in line with them. Not only did this not give us a correct understanding of what was going on but it also gave us no real new information other than what the polls themselves were telling us. I call this the redundancy argument.
- That the pollsters were committing a massive logical fallacy in extracting probability estimates from the polls (and whatever else they threw into their witches’ brew models). In fact they were dealing with a singular event (the election) and singular events cannot be assigned probability estimates in any non-arbitrary sense. I call this the logical fallacy argument.
Let us turn to the redundancy argument first. In order to explore the redundancy argument I will lay out briefly the type of analysis that I did on the polls during the election. I can then contrast this with the type of analysis done by pollsters. As we will see, the type of analysis that I was advocating produced new information while the type of approach followed by the pollsters did not. While I do not claim that my analysis actually predicted the election, in retrospect it certainly helps explain the result – while, on the other hand, the pollsters failed miserably.
Why I (Sort Of) Called The Election
My scepticism of the US election polling and commentary this year was generated by my analysis of the polls during the run-up to the Brexit referendum. All the pollsters claimed that there was no way that Brexit could go through. I totally disagreed with this assessment because I noticed that the Remain campaign’s numbers remained relatively static while the Leave campaign’s numbers tended to drift around. What is more, when the Leave campaign’s poll numbers rose the number of undecided voters fell. This suggested to me that all of those that were going to vote Remain had decided early on and the voters that decided later and closer to the election date were going to vote Leave. My analysis bore out in the election but I did not keep any solid, time-stamped proof that I had done such an analysis. So when the US election started not only did I want to see if a similar dynamic could be detected but I wanted to record its discovery in real time.
When I examined the polls I could not find the same phenomenon. But I then realised that (a) it was too far away from the election day and (b) this was a very different type of election than the Brexit vote and because of this the polls were more volatile. The reason for (b) is because the Brexit vote was not about candidates so there could be no scandal. When people thought about Brexit they were swung either way based on the issue and the arguments. If one of the proponents of Brexit had engaged in some scandal it would be irrelevant to their decision. But in the US election a scandal could cause swings in the polls. Realising this I knew that I would not get a straight-forward ‘drift’ in the polls and I decided that another technique would be needed.
Then along came the Republican and Democratic conventions in July. These were a godsend. They allowed for a massive experiment. That experiment can be summarised as a hypothesis that could be tested. The hypothesis was as follows: assume that there are large numbers of people who take very little interest in the election until it completely dominates the television and assume that these same people will ultimately carry the election but they will not make up their minds until election day; now assume that these same people will briefly catch a glimpse of the candidates during the conventions due to the press coverage. If this hypothesis proved true then any bounce that we saw in the polls during the conventions should give us an indication of where these undecided voters would go on polling day. I could then measure the relative sizes of the bounces and infer what these voters might do on election day. Here are those bounces in a chart that I put together at the time:
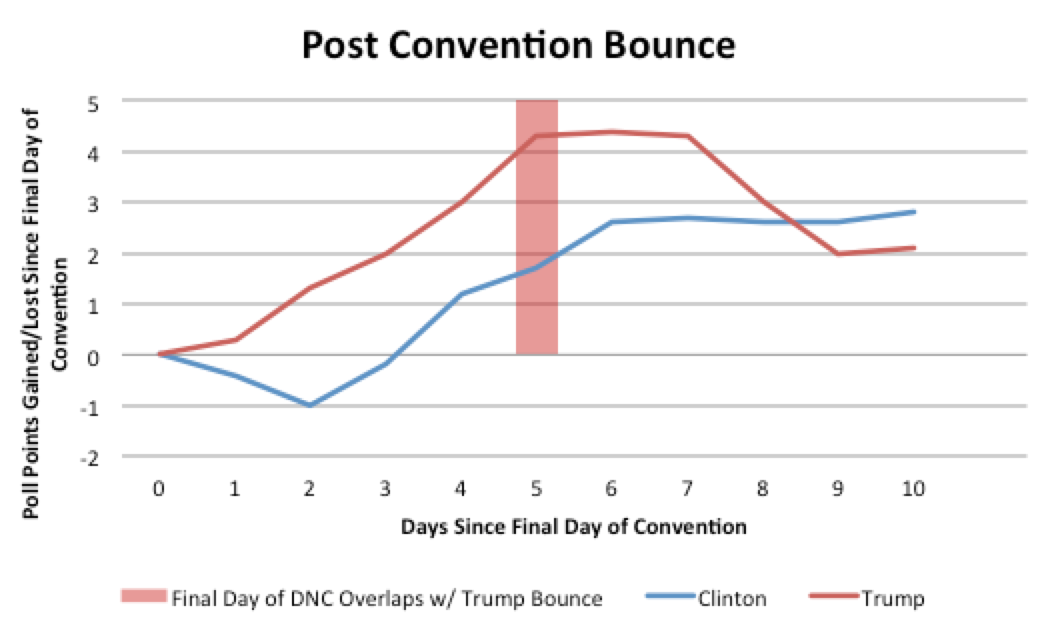
Obviously Trump’s bounce was far larger than Clinton’s. While it may appear that Clinton’s lasted longer this is only because the Democratic convention was on five days after the Republican convention so it stole the limelight from Trump and focused it on Clinton. This led to his bump falling prematurely. It is clear that the Trump bounce was much more significant. This led me to believe that undecided voters would be far more likely to vote Trump than Clinton on election day – and it seems that I was correct.
In addition to this it appeared that Trump was pulling in undecideds while Clinton had to pull votes away from Trump. We can see this in the scatterplot below.
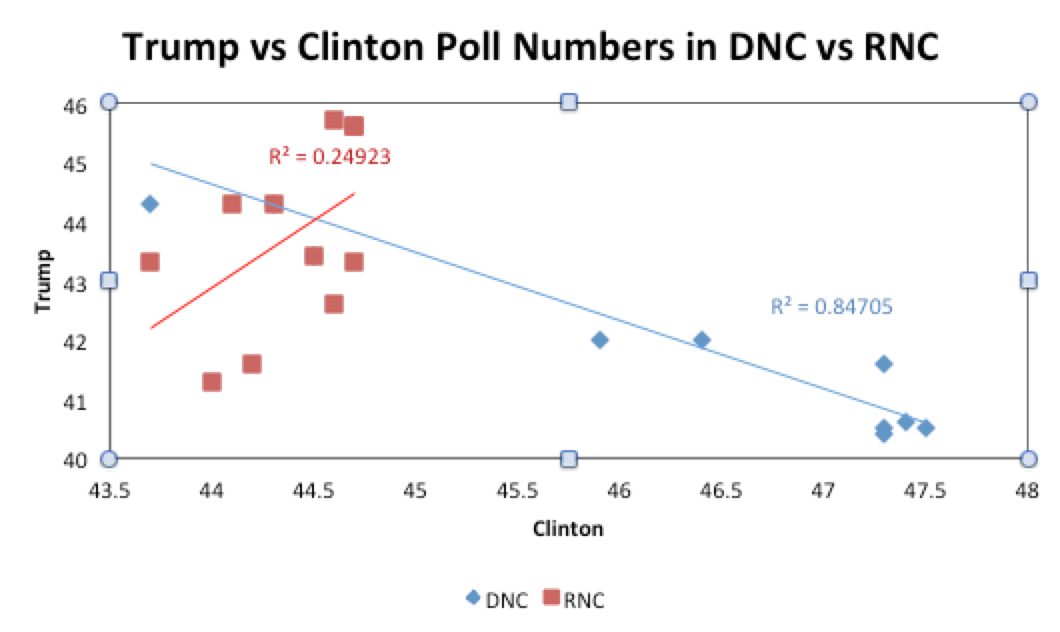
What this shows is that during the Republican National Convention (RNC) Trump’s support rose without much impacting Clinton’s support – if we examine it closely it even seems that Clinton’s poll numbers went up during this period. This tells us that Trump was pulling in new voters that had either not decided or had until now supported a third party candidate. The story for Clinton was very different. During the Democratic National Convention (DNC) Clinton’s support rose at the same time as Trump’s support fell. This suggests that Clinton had to pull voters away from Trump in order to buttress her polls numbers. I reasoned that it was far more difficult to try to convince voters that liked the other guy to join your side than it is to convince enthusiastic new voters. You had to fight for these swing voters and convince them not to support the other guy. But the new voters seemed to be attracted to Trump simply by hearing his message. That looked to me like advantage Trump.
“Aha!” you might think, “maybe you’re just faking it. How do I know that you didn’t just create that chart after the election?” Well, this is why I time-stamped my results this time around. Here are the results of my findings summarised on a piece of paper next to a Bloomberg terminal on August 9th.
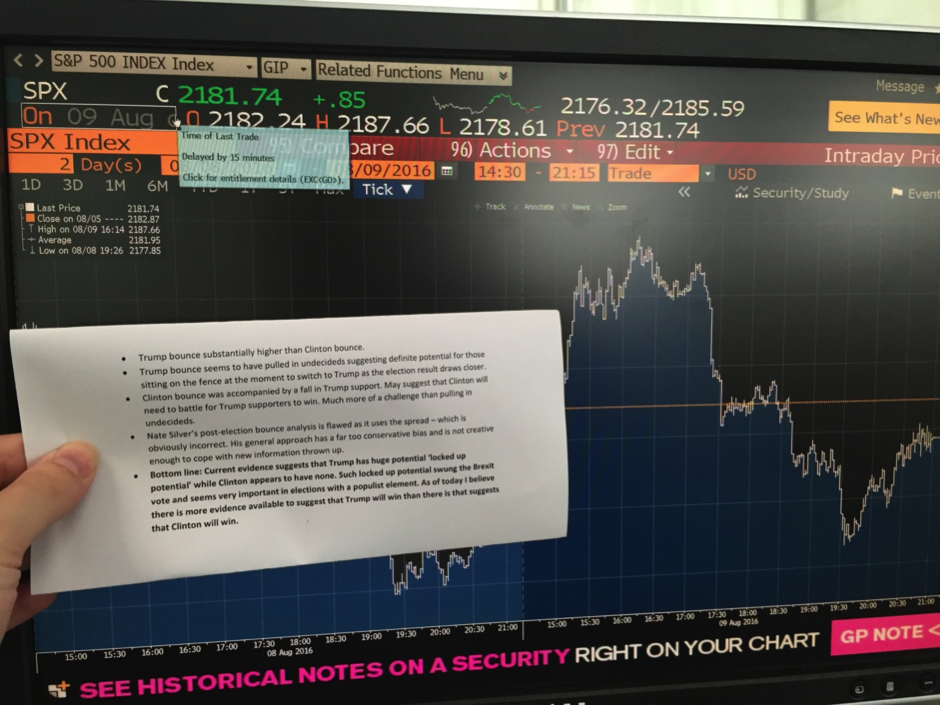
I also sent this analysis to some of the editors that are handling this piece. So they have this analysis in their email archives and can check to see that I’m not just making this up.
The reader may note that I criticise Nate Silver’s analysis in the text in the picture. I was referring to his post-convention bounce analysis in which he used the spread between the two candidates to gauge it – this was an incorrect methodology because as we have already seen the Democratic convention ate away at the Trump bounce because it came during the Trump bounce and this artificially inflated Clinton’s bounce in spread terms. The correct methodology was to consider the two bounces independently of one another while keeping in mind that the DNC stole the limelight from Trump five days after his bounce started and thereby brought that bounce to a premature halt.
This was a bad analytical error on Silver’s part but it is not actually what really damaged his analysis. What damaged his analysis significantly is that he did not pay more attention to this ‘natural experiment’ that was thrown up by the convention. Rather he went back to using his tweaked average-tracking polls. This meant that while he was following trends I was looking for natural experiments that generated additional information to that which I had from the polls. This led to Silver and other pollsters becoming trapped in the polls. That is, they provided no real additional information than that contained in the polls.
After this little experiment, as the polls wound this way and that based on whatever was in the news cycle I constantly fell back on my analysis. What was so fascinating to me was that because the pollsters simply tracked this news cycle through their models their estimates were pretty meaningless. All they were seeing was the surface phenomenon of a tumultuous and scandal-ridden race. But my little experiment had allowed me a glimpse into the heart of the voter who would only make up their mind on voting day – and they seemed to favour Trump.
Before I move on, some becoming modesty is necessary: I do not believe that I actually predicted the outcome of the election. I do not think that anyone can predict the outcome of any election in any manner that guarantees scientific precision or certainty (unless they rigged it themselves!). But what I believe I have shown is that if we can detect natural experiments in the polls we can extract new information from those polls. And what I also believe I have shown is that the pollsters do not generally do this. They just track the polls. And if they just track the polls then instead of listening to them you can simply track the polls yourself as the pollsters give you no new information. In informational terms pollsters are… simply redundant. That is the redundancy argument.
Why the Pollsters’ Estimates Are So Misleading
Note the fact that while my little experiment gave me some confidence that I had some insight into the minds of the undecided voter – more than the other guy, anyway – I did not express this in probabilistic terms. I did not say: “Well, given the polls are at x and given the results of my experiment then the chance of a Trump victory must be y”. I did not do this because it is impossible. Yet despite the fact that it is impossible the pollsters do indeed give such probabilities – and this is where I think that they are being utterly misleading.
Probability theory requires that in order for a probability to be assigned an event must be repeated over and over again – ideally as many times as possible. Let’s say that I hand you a coin. You have no idea whether the coin is balanced or not and so you do not know the probability that it will turn up heads. In order to discover whether the coin is balanced or skewed you have to toss it a bunch of times. Let’s say that you toss it 1000 times and find that 900 times it turns up heads. Well, now you can be fairly confident that the coin is skewed towards heads. So if I now ask you what the probability of the coin turning up heads on the next flip you can tell me with some confidence that it is 9 out of 10 (900/1000) or 90%.
Elections are not like this because they only happen once. Yes, there are multiple elections every year and there are many years but these are all unique events. Every election is completely unique and cannot be compared to another – at least, not in the mathematical space of probabilities. If we wanted to assign a real mathematical probability to the 2016 election we would have to run the election over and over again – maybe 1000 times – in different parallel universes. We could then assign a probability that Trump would win based on these other universes. This is silly stuff, of course, and so it is best left alone.
So where do the pollsters get their probability estimates? Do they have access to an interdimensional gateway? Of course they do not. Rather what they are doing is taking the polls, plugging them into models and generating numbers. But these numbers are not probabilities. They cannot be. They are simply model outputs representing a certain interpretation of the polls. Boil it right down and they are just the poll numbers themselves recast as a fake probability estimate. Think of it this way: do the odds on a horse at a horse race tell you the probability that this horse will win? Of course not! They simply tell you what people think will happen in the upcoming race. No one knows the actual odds that the horse will win. That is what makes gambling fun. Polls are not quite the same – they try to give you a snap shot of what people are thinking about how they will vote in the election at any given point in time – but the two are more similar than not. I personally think that this tendency for pollsters to give fake probability estimates is enormously misleading and the practice should be stopped immediately. It is pretty much equivalent to someone standing outside a betting shop and, having converted all the odds on the board into fake probabilities, telling you that he can tell you the likelihood of each horse winning the race.
There are other probability tricks that I noticed these pollsters doing too. Take this tweet from Nate Silver the day before the election. (I don’t mean to pick on Silver; he’s actually one of the better analysts but he gives me the best material precisely because of this).

Now this is really interesting. Ask yourself: Which scenarios are missing from this? Simple:
- Epic Trump blowout
- Solid Trump win
Note that I am taking (c) to mean that if the election is close or tied Silver can claim victory due to his statement of ‘*probably*’.
Now check this out. We can actually assign these various outcomes probabilities using the principle of indifference. What we do is we simply assign them equal probabilities. That means each has a 20% chance of winning. Do you see something awry here? You should. Silver has really covered his bases, hasn’t he? Applying the principle of indifference we can see that Silver has marked out 3 of the 5 possible scenarios. That means that even if we have no other information we can say that Silver has a 60% chance of ‘predicting the election’ using this statement. Not bad odds!
What is more, we can actually add in some fairly uncontroversial information. When this tweet was sent out the polls showed the candidates neck-and-neck. Surely this meant that a simple reading of the polls would tell us that it was likely to be a close call. Well, I don’t think it would be unfair to then weight the probability of (c) accordingly. Let’s say that the chance of a close call, based on the polls, was 50%. The rest of the possibilities then get assigned the rest of the probability equally – they get 12.5% each. Now Silver really has his bases covered. Without any other information he has a 75% chance of calling the election based on pure chance.
The irony is, of course, he got unlucky. Yes, I mean ‘unlucky’. He rolled the dice and the wrong number came up. Though he lost the popular vote, Trump won the electoral votes needed by a comfortable margin. But that is not the key point here. The key point here is that something else entirely is going on in this election forecasting business than what many people think is happening. What really appears to be going on is that (i) pundits are converting polls numbers into fake probability estimates arbitrarily and (ii) these same pundits are making predictive statements that are heavily weighted to being ‘probably’ correct – even if they are not conscious that they are doing this. This is really not much better than reading goat entrails or cold reading. Personally, I am more impressed by a good cold reader. The whole thing is based on probabilistic jiggery-pokery. That is the logical fallacy argument.
And Why You Should Listen to Neither of Us
Are you convinced? I hope so – because then you are being rational. But what is my point? My very general point is that we are bamboozling ourselves with numbers. Polls are polls. They say what they say. Sometimes they prove prescient; sometimes they do not. If we are thoughtful we can extract more information by analysing these polls carefully, as I did with my little experiment. But beyond this we can do little. Polls do not predict the future – they are simply a piece of information, a data point – and they cannot be turned into probability estimates. They are just polls. And they will always be ‘just polls’ no matter what we tell ourselves.
But beyond this we should stop fetishizing this idea that we can predict the future. It is a powerful and intoxicating myth – but it is a dangerous one. Today we laugh at the obsession of many Christian Churches with magic and witchcraft but actually what these institutions were counselling against is precisely this type of otherworldly prediction:
The Catechism of the Catholic Church in discussing the first commandment repeats the condemnation of divination: “All forms of divination are to be rejected: recourse to Satan or demons, conjuring up the dead or other practices falsely supposed to ‘unveil’ the future. Consulting horoscopes, astrology, palm reading, interpretation of omens and lots, the phenomena of clairvoyance, and recourse to mediums all conceal a desire for power over time, history, and, in the last analysis, other human beings, as well as a wish to conciliate hidden powers. These practices are generally considered mortal sins.
Of course I am not here to convert the reader to the Catholic Church. I am just making the point that many institutions in the past have seen the folly in trying to predict the future and have warned people against it. Today all we need say is that it is rather silly. Although we would also not go far wrong by saying, with the Church, that “recourse to mediums all conceal a desire for power over time, history, and, in the last analysis, other human beings”. That is a perfectly good secular lesson.
I would go further still. The cult of prediction plays into another cult: the cult of supposedly detached technocratic elitism. I refer here, for example, to the cult of mainstream economics with their ever mysterious ‘models’. This sort of enterprise is part and parcel of the cult of divination that we have fallen prey to but I will not digress too much on it here as it is the subject of a book that I will be publishing in mid-December 2016 – an overview of which can be found here. What knowledge-seeking people should be pursuing are tools of analysis that can help them better understand the world around us – and maybe even improve it – not goat entrails in which we can read future events. We live in tumultuous times; now is not the time


The second argument is the Bayesian vs frequentist debate on the foundations of probability theory, which has roots that go back centuries. Not that it matters, but I am in the Bayes-Laplace- Jeffreys-Jaynes camp. Evidently the author is a frequentist. But it is a vastly bigger intellectual issue than how some pollsters blew it and can’t be settled in a blog post by someone proclaiming The Truth.
Not true. What he is saying is that any prior that will be applied to the election based on polls will be arbitrary.
The critique goes beyond Bayesian vs frequentist debates in probability theory. A good Bayesian should recognise the above critique.
I based my claim on this statement–
“Probability theory requires that in order for a probability to be assigned an event must be repeated over and over again – ideally as many times as possible.”
That’s frequentism. Bayesians think that probability represents a degree of belief based on the evidence you have and your priors. It doesn’t have to require that you repeat the same event over and over again. In real life you usually can’t do this, but people still want some degree of belief assigned to the chance that it might rain tomorrow or that a hurricane will hit a certain portion of the coastline.
The rest of his critique might be perfectly valid, but the statement above is frequentist.
This is all I’m going to say. I have the uneasy feeling this could turn into some long internet debate, so my part is finished.
That applies in Bayesianism too. You set an arbitrary prior and then you update with events until you get a high level of confidence. PP is just saying that they never get beyond the setting up of an arbitrary prior.
It doesn’t depend on interpretation. The author uses two Bayesian priors when evaluating Silver’s tweet.
Before that he is simply pointing out that any prior based on the polls will be arbitrary and, because it is a single event, you will never be able to update this arbitrary prior.
Bayesian analysis is frequently cited as an alternative to frequentist schools, although only with prior awareness of the ontological challenges. Bwaaaaaaak!
The Philster is back! Dude, you’ve been gone a while.
If your title says we shouldn’t listen to you, that might discourage readers before they read. That’s a Bayesian prior. LOL. Sort of anyway.
The probability of us reading, given the admonition not to read = the probability of the admonition given the probability of us reading, divided by the probability of us reading. Or something like that. ;-)
When i do the math I get lost. I’ll read it later. Right now i can’t
My response is still making up its mind…. some where…. chortle….
But, concur with your – feelings – craazyman…. both…
Disheveled Marsupial…. I wonder what the probability is that a first commenter to Phil’s post would be an AET – neoclassical or mishmash… ummm…
PS…. Bayesian econometrics wrt VaR…. something about missing the human exploit feature for scoring a 10 bagger… despite feeding the fat tail probability contagion factor… someone else problem I guess…
man I’ve had two eaten replies here! Just having some fun ribbing the Philster.
Oh well . . . I guess I shouldn’t waste so much time.
Actually I find Phil’s posts on NC as some of the most interesting and well reasoned – critiques of Austrian and Neo-classical philosophy w/ historical perspective from a granular evidenced based methodology.
He certainly expanded my perspective, enabling me to further expand it on my own, as well as the too and fro in the comments section.
Disheveled Marsupial…. much more enlightening than humans act shtick or its all dawgs will thingy….
It doesn’t depend on interpretation. The author uses two Bayesian priors when evaluating Silver’s tweet. Before that he is simply pointing out that any prior based on the polls will be arbitrary and, because it is a single event, you will never be able to update this arbitrary prior.
yes – that statement
“Probability theory requires that in order for a probability to be assigned an event must be repeated over and over again – ideally as many times as possible. ”
jarred.
If PP had added the words “frequentist”, “Laplace”, “Venn”, “classical” in front of that, I’d let it be. But over the last 20 years, with Monte-Carlo Markov Chain methods becoming computationally feasible for more people and domains, “Bayesian”, “De-Finetti” approaches are getting their day in the sun.
I’m just adding a voice to Donald’s comment.
if anyone interestted on more…follow nassim taleb on twitter.
Taleb called the conventional wisdom’s stats BS long ago (in his typical witty mad professor style)
So did the Satanists I follow on YouTube. Their occult models were far more accurate than anything produced by the legacy media.
It’s no secret that U.S. election results can’t be audited — the integrity of the data is unknowable — and is subject to pre-election manipulation, in the form of widespread voter suppression. Post-election manipulation of vote totals also can’t be discounted, because in many election districts it wouldn’t be difficult and motive exists.
The arguments above are convincing in principle, but when the outcomes against which we measure polling predictions can’t even be verified….
Letting others debate Bayesian models… this stood out:
> This suggested to me that all of those that were going to vote Remain had decided early on and the voters that decided later and closer to the election date were going to vote Leave
Wow. Just wow. The general nature of humans is to “freak out” about big things and demand stuff like Brexit, then “calm down” and leave things roughly like they are maybe with a few touch-ups around the edges.* (This is the simplified basis of my “Brexit not gonna happen” stance.)
But this is saying that people at the last moment decided the status quo was so bad they realized they just had to make a very scary leap into something new. That, if true, says quite a lot about the status quo.
*Yes I’ve been married for quite a long time now. Why do you ask? :)
Silver called for a Brazilian victory against Germany in the 2014 World Cup. Amazing level of incompetence, and I (and millions of others) could tell before the game was played. Since then I have not visited his site.
What’s missing here is intent. There were two types of polls; the ones that attempted to REFELCT public opinion and the others that aimed to MANIPULATE voters.
Both the USC Dornsife/Los Angeles Times and the Investor’s Business Daily/TechnoMetrica Market Intelligence polls showed Trump winning. They actually both overestimated his share of the popular vote. These types of polls were also the most accurate in 2012 and were clearly just trying to show where the electorate was.
The various other MSM polls on the other hand intentionally oversampled Democrats in order to “Gaslight” the public into thinking Trump had no chance of winning and as a result these polls were voter suppression operations. But the Trump Nation knew the MSM polls were totally rigged and paid no attention to them. Instead pro-Trump pundits pimped the USC poll so hard that critics anti-Trump critics called it “Muh LA Times”
Ironically enough, the MSM PsyOps probably ended up gaslighting a number of lazy liberals into not voting since they were convinced the Hilldawg had this one in the bag. The Trumpen-proletariat on the other hand learned long ago that NBC-WSJ polls and the like are total garbage and so they avoided the gaslighting and came out to the polls in force.
*Sigh*
You don’t understand what “oversampling” means. It does NOT mean “overweighting the population in the total”. It means “sampling that population more heavily to get a more accurate estimate of how that group will act.” When you are dealing with blacks as 13% of the sample, if you sample only 13%, versus over 50% for whites (yes, the US is still a majority white country), you run the risk of the result for the black population being less accurate by virtue of having fewer observations. Given that the Dem strategy rested almost entirely on identity politics, having an good read of “minority” ethnic groups was key.
Perhaps “oversample” is not the correct word. Yes it is clear that it makes sense to “oversample” small groups such as black voters. But what I am talking about is the ratio of Democrats-Republicans-Independents (D-R-I) that they throw these results back into. Most pro-Trump commentators believed the electorate was somewhere between +2D to +2R
But for example in one ABC poll the D-R-I split was 36D-27R-31Ind which is +9D and they had Hillary up 12 points. Bring that ratio to 31D-32R-31Ind and suddenly the +12 Hillary lead becomes only +2 or so for her which is exactly what the final result was.
But surely you are not questioning my main point that the MSM polls were not an attempt to capture reality but were instead meant to create a new reality?
After some discussions about ‘the inverse Bradley effect’ some months ago, the press had been strangely silent about the effect and whether it applied to Trump. Theoretically, Trump, more than any other candidate I can name, should have enjoyed better support in the election than he was polling, as people were uncomfortable admitting that he was their preference for fear of condescension from pollsters. Ross Perot–to whom Trump is often compared– enjoyed a five point advantage ‘inverse Bradley effect’ in 1992 over his last and best poll numbers. Bill Clinton experienced a straight up ‘Bradley effect’ in both of his Presidential victories (off three points from his polling, as I recall), though he still did well enough to win.
Nate Silver had an article that pretty much outlined what happened in the election back on Sept 15th. I’m not sure why he isn’t referring to this as a fig leaf today, perhaps because so much of the rest of his reporting predicted Clinton’s victory.
http://fivethirtyeight.com/features/how-trump-could-win-the-white-house-while-losing-the-popular-vote/
I thought Clinton would likely win, but that it would be a squeaker.
“The Bradley effect” is the idea people are lying to pollsters. The problem is modeling, and unlike a few years ago, Gallup and others no longer do their daily tracking polls which give a better picture of the electorate. In the absence of a clear view of the electorate, the pollsters make up who will vote based on preconceived notions. The LaT poll was very close this cycle and last cycle for the right reasons. Why didn’t people lie to them? Are they special? They used a cross section of the country as a sample based on the census. They continued to talk to non voters or people who claimed to be non voters. They recognized people turning their backs on Team Blue. In 2012, they predicted the decline of the white vote for Team Blue and the rally of support from minorities because they talked to people.
In the case of the famed “Bradley effect,” the pollsters in that race didn’t account for high republican turnout in connection to a statewide referendum expecting the usual city council turnout. The Republicans simply weren’t counted. The “lying” of secret racists excuse was cooked up by pollsters and Bradley’s campaign to avoid accountability for not working hard enough.
I believe the FiveThirtyEight site was typically predicting a Trump win probability that ranged between 20% and 50% over the last few weeks of the campaign. Considering how close the vote was in key battleground states (often a difference of less than 30,000 votes per state), slight swings in turnout or undecided voters could easily swing the election one way or the other, which is what happened. Many of the key states had the two candidates within the margin of error close to the election and they ended up within those error bars. The US is particularly susceptible to surprises because a large percentage of the population doesn’t show up to vote. That means that variations i \n turnout is an additional variable that needs ot be understood and predicted.
I think some of the individual polls had serious sampling issues but aggregating organizations like FiveThirtyEight kept showing that Trump had a distinct possibility of winning. Since it looks like Hillary will have a small plurality of the national vote, then it is pretty clear that this was close and the actual decision is within the error bars of the best analyses.
I think a major issue is that a lot of people don’t realize that a 70/30 probability split still gives a win 30% of the time to the underdog. Anybody who watches sports knows this – it is the reason that they play the game instead of just awarding the trophy to the highest ranked team or player.
I don’t know if this fits in, but this what I’ve been pondering.
For most of my life so far, lack of turnout has been assumed to be the result of ‘voter apathy’.
It looks to me as if the democratic party’s behavior this year, especially in suppressing the Sanders campaign, had the ultimate effect of creating negative motivation on the part of many otherwise democratic voters, who were excoriated with the warning that any vote not-for-HRC was a vote for Trump.
It would seem that many of those voters accepted that reality, and by refusing to show up at the polls, did indeed vote for Trump.
From my perspective, this is both a complete repudiation of the Third-Way politics of the Clintons, and the beginning of a sea change.
What I’m saying is that we no longer have voter apathy to blame, but real evidence of deepening engagement, which hopefully bodes well for Bernie’s new project OR.
This wasn’t a mysterious failure to excite voters, it was an obvious and monumental case of ignoring the wishes of the electorate, and reaping a just reward.
In the end, faced with the prospect of the SOS, voters elected to take a chance on Change, and this included many who could not bring themselves to vote for someone who obviously did not respect them, and for whom they held no respect.
This is not your usual “poor turnout”.
I don’t know how much of the poor turnout over the past 2 decades was ever “your usual poor turnout”. Third Way servitors to the powerful were never beloved of the people, except perhaps for the charismatic Bill Clinton. And there were many of us who never understood the love for him.
Not voting has long been a conscious decision for many Americans, and when it’s a conscious decision, it’s essential a vote.
I think this is a good point. My understanding of the polling methodology is that they sample the electorate then break their sampled voters into demographic bins, then they weight the bins based on expected participation by demographic to get a final expected vote. The expected participation by demographic can really only be based on turnout from previous elections, though presumably pollsters tweak things to account for expected differences, like assuming women or latinos will be more motivated to vote in this election. If the actual turnout doesn’t match the pollsters expectation, as happened in this election, where many traditional democratic demographics appeared to be demotivated, then the polls will all be systematically inaccurate.
Putting blame for voter ‘apathy’ on Clinton’s treatment of the Democratic base that supported Sanders, probably the most activist part of the party, or on Clinton’s pivot to ‘suburban republicans’, or on the FBI, or Clinton’s disastrous foreign policy record, or Clinton’s unprecedentedly low favorability and trustworthiness numbers is difficult, but all of those problems were foreseen by Sanders supporters as well as by the DNC, but were ignored by the latter. That those problems were likely to depress turnout, which Democrats need to win elections was also fairly obvious, which is why I never believed the polls and believed Trump was indeed likely to win.
And of course another major factor is that the polls were seemingly sponsored by media organizations which have pretty openly declared their opposition to Trump. The obvious suspicion was, then, that the polls were intended as campaign propaganda rather than objective information, and were tweaked (via turnout models?) to make Hillary seem inevitable. I also believed this was likely to lead to complacency among democrats, since Republicans are very reliable voters, and Trump-inspired indies would not believe anything coming from the MSM anyway.
Most people I dared to explain this too were incredulous, and tended to write it off as more of my characteristic weird logic… and now they are shocked, the idiots.
Perhaps one of the reasons that the LATimes/USC poll got it right was that amongst the key questions asked of their 3200-person tracking base was “enthusiasm for one’s candidate”; the fact that over 6mil Obama voters apparently walked away from Clinton’s voter cohort lends some credence for the importance of such a parameter. Where they went is less important that in fact such a significant group somehow were not accounted for by mainstream polling. Alan Lichtman’s model has 13 keys of which these are two:
Key 12: The incumbent-party candidate is charismatic or is a national hero.
Key 13: The challenger is not charismatic and is not a national hero.
Now, surely there is no doubt that both keys would be answered as false, and which would point toward a plus for Trump, and also serve as a proxy for “enthusiasm” or lack thereof for one’s candidate. And, no doubt at all, Trump supporters were over-the-top enthusiastic for their man and voted in numbers accordingly, whilst Clinton supporters rather wearily accepted (“It’s her turn”) her candidacy and did or did not actually show up and vote for her.
That it was long and widely debated which one of these scum was actually the lesser of 2 evils should have been a clue about enthusiasm as well.
Presumably the LATimes/USC pollsters weighted their turnout model with an enthusiasm factor… good on ’em!
Speaking of “her turn,” here’s a simpler version of Alan Lichtman’s 13 keys — just one key. Posted Jan 5, 2016 at 8:15 pm:
This model implies that Trump wins re-election in 2020, and that a Democratic president takes over from him in 2024.
It takes extraordinary circumstances to disrupt the 8-year rotation, which is now a structural feature of the constitution (Amendment XXII).
Polling organizations are really political organizations that get paid to influence public opinion rather than measure it. Their models are garbage. It’s a complete joke of an industry.
Actually that just under 2 percent win in the national polls is going to be correct. Also many polls were vert close in PA were close as was FL and NC . Very few were done in Michigan which AP may never call because it is close enough for a recount. In the national number it looks like a 1 or 2 win
Good to see that Phil is out of grad school and holding down a real job. Hope he posts to NC again soon.
And soon to be author ‘The Reformation in Economics: A Deconstruction and Reconstruction of Economic Theory’.
I thought the media and the both campaigns got it so wrong because they think everyone everywhere is on Facebook and Twitter. The people that helped elect the Trumpeter aren’t on social media and didn’t exist to those in power.
Surprise.
Completely subjective, I doubted the polls because of the media coverage. I found the propaganda so over the top, I expected that pollsters were doing the same. Whether it was pressure to conform in the industry, groupthink, ideology as algorithm, I had no idea. Just noting that Clinton’s camp was very dependent on an algorithm and that failed. I find striking PP’s observation of the relative consistency in one side of Brexit compared to the relative volatility on the other side of Brexit to the Clinton/Trump election. I recall people for the US 2016 cycle looking at the polling questions, the wording of the questions and the yelling ‘they aren’t asking the right questions’ and lots of declarations that the polls were just garbage.
In 2008, it was easy to look up the demographics in a region (census data by county was sufficient), look at the immediate economic conditions and shifts, (didn’t even need a recent vote to detect voter shift), pop it into a spread sheet at home and make an accurate estimate of the vote.
I’ll be watching to see if volatility in polling on one side of an equation is a factor next voting cycle.
A little off topic, but since Nate Silver gets a lot of heat (some deserved, some overdone), it is worth pointing out that this particular tool of his actually worked quite well and was revealing.
http://projects.fivethirtyeight.com/2016-swing-the-election/
So some of his data and analytics work is still good, even if his commentary is crap and he fudges some things too much and misreads others.
I am unable to assume that the pollsters were even close to legitimate. I believe they intentionally tweaked every possible variable to keep Hillary “close” to Trump and/or winning by 5%. Now they are saying she won the popular vote and Trump should step aside (Michael Moore unmoored). When Trump was paranoid about the way every bit of good news about his candidacy was turned to bad news or ignored within a few hours, he was noticing a very concerted effort to stop him. It isn’t too much to imagine then that many of the poll surveys were rigged and that electronic voting was likewise rigged by an app that gave every 5th Trump vote to Hillary. It’s all possible, and in the end they just couldn’t steal enough votes – which means that the reason they rigged the polls in the first place is because Trump was always way out in front and we know they were horrified.
What I don’t understand is why the vast majority is mentally locked into the party duopoly, even Sanders voters. Sheeple?
All of the Media focused on Clinton. When the Media did a story on Trump
it was negative. The Media never listened to what the people had to say.
This is why the people now DO NOT TRUST THE MEDIA.
They bought too few votes. I have no doubt that Clinton and Soros and other like minded had the voting system rigged via the Diebold voting machines.
They simply underestimated how many votes were required, and didn’t buy enough.
the press was bought and paid for as well, you only need to control perhaps 10 people, and you control almost the entire established press!
Lastly, schooling and indoctrination didn’t work as well as they thought they had some people shamed and framed, but not enough. Some will simply just not lie down and admit that you are not allowed to be racist/fascist/homophobe/ or whatever is the PC terms at any given moment.
People have had enough of more than 30 years of indoctrination, abuse, belittlement and contempt.
Yes. Saw Bev’s posts in links and while personally inclined to support the integrity of the process above partisan results, does anyone think Team D didn’t try to stuff mail-in ballots, rig votes, put states in the bank ‘no matter what’ (NV?), maybe or maybe not put the Bernie voters they disenfranchised during the primaries back on the rolls (not, if they might become Trump voters), rack up 5 million provisional ballots in CA, many perhaps near more-conservative San Diego, etc., etc., also fill in whatever you observed during the primary (there was a lot).
Not to mention they ran a horrific campaign, repeatedly kicked their own base & gave millions – enough to obliterate the margin of their loss in MI for example – every other conceivable reason to stay home, transparently rigged the media, ran on fear and anything but their ‘most progressive platform in history,’ and to top it all off promised the nation and the world a go at WWIII. They also tried to ‘thread the needle’ and skate through the primaries by not registering voters for fear of their subsequently voting ‘incorrectly,’ and then, in a deeply anti-establishment election, assumed that they would poach voters (enough to win!) from the other side with a candidate uniquely hated by opposing partisans and probably most independents.
Yikes. If they didn’t lose the election ‘fairly,’ they certainly deserved to.
The polls and the commentary that accompanies them, including probability modeling, are entertainment products. If the entertained people, they were successful.
Dewey Defeats Truman
Hillary Beats The Donald
Polls? Who will rid us of these troublesome menaces???
Pilkington’s convention bounce hypothesis is easily generalizable to other elections. It would be interesting to see how it holds up when that is done.
Persoanly I thought more would have noticed the thread weaving through the post about convention [regardless of agency issues] becoming a religion and such devices its iconography. Which at the end of the day does as is such group thinks want… increase the friction in new discovery or out right banish it… because – truth – has been reveled thingy…
Philosophy [or sophistry] is comported to maths and physics until it become a twisted corrupt parody where noone remembers the original priori or its birth let alone its lineage…. a thin intellectual gruel or worse palliative Bernays cortex injection for the unwashed….
Disheveled Marsupial…. ref – unwashed… the beautiful when not observing the rites and rituals of maintaining a small deity statue reference point with reality…. would stare at their mirrors…. confirming their bias of who and what they were… in reference – too – the unwashed….
Ok, I admit it I’m hopelessly confused: why is everyone saying the polls were wrong?
They missed by 2 points, well within the historical accuracy of national polls. Good aggregators (Silver) had a 30% chance of a Trump win, and their maps look correct when you build in a (perfectly reasonable) two point miss.
Less good aggregators handled the correlations incorrectly (generally by ignoring them), and this was a very well known criticism of them before the election (or even before this year). This is not a failure of polling but a (gross, long-recognized, and long-uncorrected) failure of aggregate modeling.
Aside: even Sam Wang’s site gave a pretty reasonable estimate of the probability, if you ignored the headline probability and used a historical distribution of polling error together with his calculated Meta-margin. (He’s the one who ate a bug.)
Post facto it’s easy to pick out polls that were closer and further away. But the cardinal sin of data analysis is “tuning your cuts on the data”: it makes your discoveries always look more significant than they really are.
What I see is that the polls were wrong if you had an unreasonable expectation for their accuracy.
I don’t think that the above article was making criticisms based on whether polls were wrong.
And incidentally, no one really expected Trump to win. Come on. Don’t BS. The author’s call (made back in August) was WAY against the grain.
Not post facto (I got a lot of guff from my Clinton friends for pointing this out in the week before Tuesday): a 4.5 point favorite (which is what the Clinton margin of 3 translated to, electoral college wise) loses a game nearly every Sunday. It’s not BS to point out that that doesn’t make the line wrong.